Aufgabe 1
In der Kardiologie wurde eine Kohortenstudie () durchgeführt, in der das Auftreten einer milden unerwünschten Arzneimittelwirkung (UAW) in Abhängigkeit von folgenden potenziellen Risikofaktoren untersucht werden sollte:
| Variable | Beschreibung |
|---|---|
| Statin | Statin verordnet / Statin nicht verordnet |
| Alter | in Jahren |
| Geschlecht | weiblich / männlich |
| Hämatokrit | in g/dl |
Die Referenzkategorie ist jeweils unterstrichen.
Für die Auswertung wurde ein logistisches Regressionsmodell angewendet. Im Folgenden sehen Sie einen Teil des R-Outputs für das Endmodell ():
Coefficients:
| Coefficient | Estimate | Std. Error |
|---|---|---|
| (Intercept) | -1.75544 | 0.78492 |
| Statin | 0.14692 | 0.26833 |
| Geschlecht | 0.37668 | 0.18705 |
| Alter | 0.03694 | 0.01383 |
| Statin:Geschlecht | 1.12018 | 0.34857 |
(a) In diesem Datensatz gibt es 33 Frauen, die 54 Jahre alt sind und denen Statin verordnet wurde. Bei wie vielen dieser Frauen erwarten Sie eine UAW?
Logistische Regressionsmodelle und Log-Odds nicht verstanden? → Logistische Regression Odds vs. Wahrscheinlichkeit
Um die erwartete Anzahl der Frauen mit UAW zu berechnen, verwenden wir das logistische Regressionsmodell:
-
Log-Odds berechnen:
Einsetzen der Koeffizienten und Werte (Statin = 1, Geschlecht = 1 (weiblich), Alter = 54):
-
Odds in Wahrscheinlichkeit umrechnen:
-
Erwartete Anzahl:
Antwort: Bei etwa 28 der 33 Frauen erwarten wir eine UAW.
(b) Berechnen Sie das Odds Ratio der unter (a) definierten Patientengruppe im Vergleich zu Männern, die kein Statin verordnet bekamen und 73 Jahre alt sind.
Einsetzen
Log-Odds beider Gruppen
Wichtig
Du hast kein Plan warum wir diese Formel brauchen? → Erklärung Warum wir die Differenz der Log-Odds verwenden und nicht die Division
- Frauen mit Statin (54. Jahre)
- Männer ohne Statin (73 Jahre)
Differenz dieser log Odds
Tipp
Du hast kein Plan warum wir hier subtrahieren und nicht dividieren? → Erklärung Warum wir die Differenz der Log-Odds verwenden und nicht die Division
Damit nun Odds berechnen
→ Die OR dafür, dass eine Frau mit Statin im Alter von 54 Jahren eine UAW hat ist ungefähr 2.56 mal größer als ein Mann ohne Statin im Alter von 73 Jahren
(c) Überprüfen Sie anhand eines geeigneten Tests, ob der Effekt von Alter statistisch signifikant ist. Berechnen Sie analog für den Regressionskoeffizienten von Alter ein 95%-Wald-Konfidenzintervall.
Wald-Test – Kurz & Knackig
Zweck: Prüft, ob ein Regressionskoeffizient (z. B. für Alter) signifikant von Null abweicht.
Formel & Schritte
- Teststatistik berechnen:
- Entscheidung:
- Kritischer Wert bei : .
- → Signifikanter Effekt ().
Beispiel – Alter in der Studie
- , .
- Teststatistik:
95%-Wald-Konfidenzintervall
- Formel:
- Berechnung:
- Interpretation:
- Intervall enthält nicht die Null → Alter ist signifikant.
- Effektstärke: Pro Lebensjahr steigen die Log-Odds für UAW um 0.0098 bis 0.0640.
Warum Wald-Test?
- Vorteile:
- Schnell: Nutzt direkt und aus der Regression.
- Keine zusätzlichen Modellrechnungen nötig (z. B. beim LRT).
- Nachteil: Bei kleinen Stichproben () ungenau → besser LRT.
Typische Fragen
Frage: “Warum steht im Output ein -Wert und kein -Wert?”
Antwort: In der logistischen Regression wird asymptotische Normalverteilung angenommen (große ) → -Werte.Frage: “Was, wenn das KI die Null einschließt?”
Antwort: Dann ist der Effekt nicht signifikant (z. B. KI ).Zusammenfassung
- Wald-Test = Der Schnellcheck für Signifikanz in Regressionen.
- Merksatz:
“Z-Wert über 1.96 – der Effekt ist nicht von Null!” 😉
1. Überprüfung der statistischen Signifikanz des Alterseffekts
a) Wahl des Tests:
Um zu prüfen, ob der Effekt des Alters signifikant ist, verwenden wir den Wald-Test.
Warum?
- Der Wald-Test nutzt direkt den geschätzten Koeffizienten () und seinen Standardfehler () aus dem Regressionsoutput.
- Er ist einfach durchzuführen, da keine zusätzlichen Modellrechnungen (z. B. Likelihood-Ratio-Test) erforderlich sind.
- Bei großen Stichproben () ist der Wald-Test zuverlässig.
b) Berechnung der Teststatistik:
c) Entscheidung:
- Kritischer Wert bei (zweiseitig): .
- Da , lehnen wir die Nullhypothese ab.
- Ergebnis: Der Effekt des Alters ist statistisch signifikant ().
2. Berechnung des 95%-Wald-Konfidenzintervalls für (Alter)
a) Formel:
b) Berechnung:
c) Interpretation:
- Das 95%-Konfidenzintervall für ist .
- Da die Null nicht im Intervall liegt, bestätigt dies die Signifikanz des Alterseffekts.
- Effektstärke: Pro zusätzlichem Lebensjahr steigen die Log-Odds für eine UAW um 0.0098 bis 0.0640.
- Odds Ratio: bis .
3. Fazit
- Alter hat einen signifikant positiven Einfluss auf das Auftreten einer UAW ().
- 95%-Konfidenzintervall: .
- Praxisrelevanz: Obwohl der Effekt klein ist, ist er statistisch nachweisbar.
(d) Ein Kollege berechnet ein weiteres logistisches Regressionsmodell, indem er zusätzlich den potenziellen Einflussfaktor Hämatokrit berücksichtigt. Der entsprechende R-Output für das Endmodell lautet:
Coefficients:
| Coefficient | Estimate | Std. Error |
|---|---|---|
| (Intercept) | 1.84289 | 0.79758 |
| Statin | -0.14232 | 0.26846 |
| Geschlecht | -0.37883 | 0.18714 |
| Alter | -0.03702 | 0.01384 |
| Hämatokrit | -0.16562 | 0.25825 |
| Statin:Geschlecht | -1.12703 | 0.34881 |
Was fällt Ihnen auf? Können Sie dieses Ergebnis „reparieren“?
Multikollinearität – Kurz erklärt
Was ist das?
Multikollinearität liegt vor, wenn zwei oder mehr Prädiktoren in einem Regressionsmodell stark korreliert sind. Das führt dazu, dass die Schätzung der Koeffizienten instabil wird (z. B. Vorzeichenumkehr) und schwer interpretierbar ist.Warum ist das ein Problem?
- Die Effekte der korrelierten Variablen lassen sich nicht mehr eindeutig trennen.
- Standardfehler der Koeffizienten werden aufgebläht → Signifikanztests unzuverlässig.
Wie erkennt man es?
- Variance Inflation Factor (VIF):
- VIF > 5: Moderate Multikollinearität.
- VIF > 10: Schwere Multikollinearität.
- Korrelationsmatrix: Prüfe, ob Prädiktorenpaare Korrelationen > |0.7| haben.
Beispiel aus der Aufgabe (d):
Nach Hinzufügen von Hämatokrit kehren sich die Vorzeichen anderer Koeffizienten um. Mögliche Ursache: Hämatokrit ist stark mit Alter oder Geschlecht korreliert.Lösungen:
- Variablen entfernen: Den am wenigsten theoriefundierten Prädiktor streichen.
- Daten kombinieren: Aus stark korrelierten Variablen einen Index bilden (z. B. PCA).
- Mehr Daten sammeln: Reduziert zufällige Korrelationen.
Typische Fragen
”Warum nicht einfach Korrelationen prüfen?”
→ Die VIF berücksichtigt alle Prädiktoren gleichzeitig, nicht nur paarweise Korrelationen.”Was tun, wenn ich Variablen nicht entfernen darf?”
→ Ridge-Regression verwenden, die Multikollinearität stabilisiert.Merksatz:
“VIF über 5? 🚩 – Zeit zum Handeln!” 😉
Auffälligkeiten
-
Vorzeichenumkehr:
Die Koeffizienten für Statin, Geschlecht, Alter und Statin:Geschlecht haben im Vergleich zum ursprünglichen Modell gegenläufige Vorzeichen (z. B. Statin: von +0.14692 auf -0.14232). Dies deutet auf Multikollinearität oder eine fehlende Interaktion hin. -
Fehlende Interaktion:
Es gibt einen Interaktionsterm Statin:Geschlecht, aber keinen Term Hämatokrit:Geschlecht. Falls der Effekt von Hämatokrit geschlechtsspezifisch ist, verzerrt dies die Schätzungen.
Reparatur-Schritte
-
Interaktion hinzufügen:
Erweitere das Modell um Hämatokrit:Geschlecht:formula = UAW ~ Statin + Geschlecht + Alter + Hämatokrit + Statin:Geschlecht + Hämatokrit:GeschlechtBegründung: Der Effekt von Hämatokrit könnte bei Frauen und Männern unterschiedlich sein.
-
Multikollinearität prüfen:
Berechne die Variance Inflation Factors (VIF) für alle Prädiktoren:- VIF > 5 → Prädiktor entfernen/kombinieren.
- Verdacht: Hämatokrit könnte mit Alter/Geschlecht korrelieren.
-
Modell neu anpassen:
Nach Hinzufügen der Interaktion prüfen, ob sich die Vorzeichen stabilisieren.
Ergebnis
- Durch Hämatokrit:Geschlecht werden geschlechtsspezifische Effekte abgebildet.
- Die Vorzeichenumkehr der anderen Koeffizienten verschwindet wahrscheinlich.
Antwort:
Das Modell lässt sich reparieren, indem man Hämatokrit:Geschlecht hinzufügt und Multikollinearität prüft.
(e) Die Devianz des Regressionsmodells aus Aufgabe (a) beträgt 1028,437, die Devianz des Regressionsmodells aus Aufgabe (d) beträgt 1028,849. Führen Sie einen Likelihood-Quotienten-Test (LRT) durch und interpretieren Sie das Ergebnis.
Hinweis: Die Devianz ist definiert für ein Modell als , wobei die Likelihood des saturierten Modells ist (nicht angegeben).
Schritte des Likelihood-Quotienten-Tests (LRT)
-
Nullhypothese (): Das komplexere Modell (d) mit Hämatokrit bietet keinen signifikanten Vorteil gegenüber dem einfacheren Modell (a).
-
Teststatistik:
Hinweis: Ein negativer Wert bedeutet, dass das komplexe Modell eine schlechtere Anpassung hat als das einfache Modell.
-
Entscheidung:
- Die Teststatistik folgt einer -Verteilung mit (weil Modell (d) 1 zusätzlichen Parameter enthält).
- Kritischer Wert bei : .
- Da , kann nicht verworfen werden.
Interpretation
- Ergebnis: Das Hinzufügen von Hämatokrit verbessert das Modell nicht signifikant ().
- Praktische Bedeutung: Hämatokrit trägt in diesem Kontext nicht zur Erklärung der UAW bei.
- Achtung: Der negative LRT-Wert deutet darauf hin, dass das komplexe Modell sogar schlechter passt als das einfache Modell – ein klares Zeichen, dass Hämatokrit keinen Nutzen hat.
Aufgabe 2
In einer Studie mit Personen wurde der Zusammenhang zwischen der Lebenszufriedenheit einer Person und der Anzahl ihrer positiven Tagesereignisse in den letzten 24 Stunden untersucht. Personen markierten auf einer Liste von 30 positiven Tagesereignissen alle, die sie in den letzten 24 Stunden erlebt hatten. Die abhängige Variable Lebenszufriedenheit wurde anhand des Items „Ich bin mit meinem Leben zufrieden“ erfasst. Der Antwort „ja“ wurde der Wert 1, der Antwort „nein“ der Wert 0 zugeordnet. Eine Analyse des Zusammenhangs beider Variablen auf Basis einer logistischen Regression mit Prädiktor ergab folgende Ergebnisse: und .
(a) Stellen Sie das zugehörige Regressionsmodell auf und interpretieren Sie die Parameter und .
Unzureichende Lösung
- steht für die Grundlebenszufriedenheit, die eine Person hat, unabhängig von der Anzahl ihrer positiven Tagesereignisse
- steht für die zusätzliche Lebenszufriedenheit, die pro Anzahl der positiven Tagesereignisse der Personen zur Grundlebenszufriedenheit addiert wird.
Regressionsmodell:
Interpretation der Parameter:
-
:
Dies ist der log-Odds der Lebenszufriedenheit, wenn eine Person keine positiven Tagesereignisse hatte ().- Inhaltlich: Bei beträgt die Wahrscheinlichkeit für “Ja” etwa (sehr knapp über 50%).
- Formulierungen wie “Grundlebenszufriedenheit” sind intuitiv, sollten aber klar auf den log-Odds-Bezug hinweisen.
-
:
Dieser Koeffizient gibt die Änderung der log-Odds der Lebenszufriedenheit pro zusätzlichem positiven Tagesereignis an.- Einfacher ausgedrückt: Mit jedem positiven Ereignis erhöhen sich die log-Odds um .
- Odds-Ratio-Interpretation: Die Odds selbst vervielfachen sich pro Ereignis um (d. h., sie steigen um etwa ).
Kritik an meiner eigentlichen Lösung:
- Die Formulierung “zusätzliche Lebenszufriedenheit” ist irreführend, da es sich nicht um eine direkte Erhöhung der Lebenszufriedenheit (als metrische Variable), sondern um die log-Odds der binären Antwort handelt.
- Präzisieren Sie, dass und Effekte auf der Skala der logarithmierten Chancen abbilden.
Korrekte Kurzantwort:
- : Log-Odds der Lebenszufriedenheit bei .
- : Erhöhung der log-Odds pro zusätzlichem positiven Ereignis.
(b) Wie ändern sich die Chancen für Lebenszufriedenheit, wenn die Anzahl an positiven Tagesereignissen um 10 ansteigt?
Lebenszufriedenheit mit 10 positiven Tagen
Man sollte die Wahrscheinlichtkeit nicht berechnen nur die Chance (Odds)
Lebenszufriedenheit mit 0 positiven Tagen
- Ergebnis:
Man sollte die Wahrscheinlichtkeit nicht berechnen nur die Chance (Odds)
Antwort
Man sollte die Wahrscheinlichtkeit nicht berechnen nur die Chance (Odds)
→ Die Lebenszufriedenheit steigt um
→ Die Chancen für Lebenszufriedenheit verdoppeln sich (Odds-Ratio ≈ 2.07), wenn die Anzahl positiver Tagesereignisse um 10 steigt.
(c) Berechnen Sie die Wahrscheinlichkeit, mit dem Leben zufrieden zu sein, für eine Person, die 10 positive Tagesereignisse angegeben hat.
→ Eine Person die 10 positive Tagesereignisse angegeben hat, hat eine Wahrscheinlichkeit zufrieden mit dem Leben zu sein
(d) Plotten Sie in die Wahrscheinlichkeit, mit dem Leben zufrieden zu sein, in Abhängigkeit von der Anzahl an positiven Tagesereignissen.
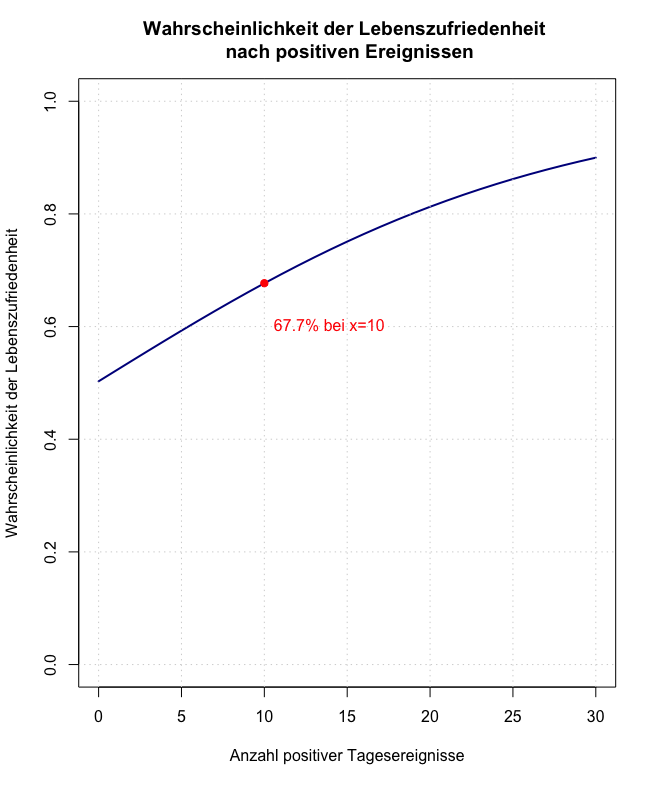
# Koeffizienten aus der logistischen Regression
beta0 <- 0.0113
beta1 <- 0.0728
# Bereich der positiven Tagesereignisse (0 bis 30, da 30 die maximale Anzahl ist)
x <- seq(0, 30, by = 1)
# Berechnung der Wahrscheinlichkeiten P(Y=1)
log_odds <- beta0 + beta1 * x
prob <- exp(log_odds) / (1 + exp(log_odds)) # Alternativ: plogis(log_odds)
# Plot erstellen
plot(x, prob,
type = "l", # Linienplot
col = "darkblue",
lwd = 2,
xlab = "Anzahl positiver Tagesereignisse",
ylab = "Wahrscheinlichkeit der Lebenszufriedenheit",
main = "Wahrscheinlichkeit der Lebenszufriedenheit nach positiven Ereignissen",
ylim = c(0, 1)) # Y-Achse von 0 bis 1
# Raster hinzufügen
grid()
# Hervorhebung des Beispiels aus Teil (c): x = 10
points(10, 0.677, col = "red", pch = 19)
text(10, 0.6, "67.7% bei x=10", col = "red", pos = 4)