Höchstleistungsrechner
Aufgabe 2.1: Ein neuer Höchstleistungsrechner
Angenommen, Sie sind Direktor eines Rechenzentrums und sollen einen neuen Höchstleistungsrechner beschaffen. Wie würden Sie vorgehen? Gehen Sie im Detail auf folgende Fragen ein:
- Welche Bewertungskriterien würden Sie wählen?
- Wie würden Sie die Benchmarks bestimmen?
- Wenn Ihre Beschaffung auf TCO (Total-Cost-of-Ownership) basiert, welche Optimierungen müssen die Anbieter durchführen?
💡 Was sind TCO im Rechenzentrum
Die Total Cost of Ownership (TCO) beschreibt alle Kosten, die während des gesamten Lebenszyklus eines Rechenzentrums entstehen. Sie dient als wichtige Grundlage, um Investitionen und Betriebskosten zu planen und zu optimieren.
- Kapitalausgaben (CAPEX): Dazu zählen einmalige Anschaffungskosten wie der Bau des Rechenzentrums, die Beschaffung von Hardware (Server, Netzwerktechnik) und Infrastruktur (Klimaanlagen, Stromversorgung).
- Betriebskosten (OPEX): Hierzu gehören laufende Ausgaben wie Stromverbrauch, Wartung, Personalgehälter, Kühlung und regelmäßige Hardware- oder Software-Upgrades.
- Indirekte Kosten: Auch versteckte Kosten, z. B. durch Ausfallzeiten, ineffiziente Kühlung oder mangelnde Skalierbarkeit, fließen in die TCO ein.
Das Ziel ist es, die TCO durch effiziente Planung, nachhaltige Technologien und Reduktion von Betriebskosten langfristig zu minimieren.
-
Bewertungskriterien
- Standortwahl:
- Der erste Schritt den ich in Erwägung ziehen würde, wäre einen gut geeigneten Standort zu finden. Der muss genug Platz bieten und von den geographischen Umständen her geeignet sein, damit das Rechenzentrum dort langfristig betrieben werden kann. Idealerweise liegt der Standort etwas außerhalb einer Stadt, aber mit einer stabilen und leistungsfähigen Stromversorgung. Die Nähe zu Hochschulen oder Instituten wäre von Vorteil, um potenzielle Nutzer direkt anzusprechen. Dabei würde ich auch darauf achten, dass die Infrastruktur vor Ort passt, also schnelle Internetanbindung, Sicherheit (z. B. keine Hochwassergefahr) und Zugang zu nachhaltigen Energieressourcen wie Solar- oder Windkraft.
- Use-Case-Definition:
- Danach würde ich mir überlegen, was genau das Rechenzentrum leisten soll. Wird es primär für wissenschaftliche Berechnungen genutzt oder auch für rechenintensive Aufgaben wie Simulationen oder Grafikanwendungen, die hohe GPU-Leistung erfordern? (Rechenzentren können nicht alles gleich gut, der SuperMUC zum Beispiel absolut nicht fürs Bitcoin-Mining gemacht um es überspitzt zu erklären). Abhängig vom Use-Case könnte ich dann auch gezielt überlegen, welche Universitäten, Forschungsinstitute oder Unternehmen Interesse hätten, die Kapazitäten des Rechenzentrums zu nutzen. Der Standort könnte wie oben schon erwähnt im besten Fall so gewählt sein, dass die Zielgruppe gleich in der Nähe ist.
- Finanzierung und Partner:
- Sobald klar ist, was und wo ich bauen will, würde ich Sponsoren und Partner suchen, die das Projekt unterstützen. Firmen wie Lenovo haben beim SuperMUC-NG gezeigt, wie solche Kooperationen erfolgreich umgesetzt werden können. Gleichzeitig würde ich Fördermittel beantragen, z. B. bei der EU oder nationalen Forschungseinrichtungen. Hier ist ein solider Meilensteinplan entscheidend, der zeigt, wie das Projekt umgesetzt wird und welche Vorteile es bringt.
- Technische Umsetzung:
- Sobald diese grundlegenden Dinge feststehen, geht’s an die Umsetzung. Hier würde ich mich um die Details kümmern: Stromversorgung (am besten nachhaltig), effiziente Klimatisierung, Brandschutzmaßnahmen und Monitoring-Systeme, die den Betrieb überwachen. Besonders wichtig wären auch Redundanzen, um Ausfälle zu vermeiden, und natürlich ein Augenmerk auf Energieeffizienz, damit das Rechenzentrum nicht zum Stromfresser wird. Mit modernen Technologien könnte man z. B. auch die Abwärme sinnvoll nutzen, um Gebäude zu beheizen oder in anderen Prozessen weiterzuverwenden.
- Standortwahl:
-
Benchmarks bestimmen
- Auslastung:
- Ich würde typische Workloads simulieren, um die Effizienz des Systems bei verschiedenen Anwendungen wie wissenschaftlichen Berechnungen oder KI-Trainings zu messen.
- Verfügbarkeit:
- Ein wichtiger Benchmark ist die tatsächliche Verfügbarkeit des Systems. Ziel ist eine möglichst hohe Betriebszeit (z. B. 99,9 %), auch bei voller Auslastung.
- Geplante Nichtverfügbarkeit:
- Wartungszeiten sollten minimal und vorhersehbar sein. Tests würden zeigen, wie schnell und effizient Updates oder Reparaturen durchgeführt werden können.
- HV-Benchmark (BSI):
- Nach einer kurzen Recherche habe ich den HV-Benchmark des BSI gefunden (HV-Benchmar vom BSI) , der sich als passender Standard für die Bewertung der Hochverfügbarkeit eines Rechenzentrums eignet. Er berücksichtigt Faktoren wie Wiederherstellungszeiten, Verfügbarkeitsklassen und Ausfallsicherheit und ermöglicht damit eine systematische Bewertung.
- Auslastung:
Zusätzlich könnten technische Benchmarks wie LINPACK (Rechenleistung), IOzone (Speicherzugriffe) oder Energieeffizienztests ergänzt werden, um ein umfassendes Bild der Systemleistung zu erhalten.
- Welche Optimierungen müssen die Anbieter durchführen?
- Verringerung menschlicher Fehler:
- Man nehme an, ein Forscher führt seine Berechnungen auf einem Supercomputer aus. Wenn der Code aber nicht optimiert ist, sei es in der Laufzeit oder beim Speicherverbrauch, gehen unnötig viele CPU-Stunden drauf, und das kostet. Anbieter könnten hier mit Tools helfen, die ineffizienten Code erkennen, und so Ressourcenverschwendung vermeiden.
- Zuverlässigkeit und Betriebszeit:
- Ein Supercomputer bringt nur was, wenn er läuft. Die Instandhaltung sollte so effizient wie möglich sein, damit Ausfälle minimiert werden. Monitoring-Systeme und Redundanzen könnten hier den Unterschied machen.
- Skalierbarkeit:
- Systeme sollten modular aufgebaut sein, sodass man bei steigendem Rechenbedarf einfach zusätzliche Kapazitäten hinzufügen kann, ohne alles von Grund auf umbauen zu müssen.
- Energieeffizienz:
- Supercomputer produzieren eine Menge Abwärme. Warum nicht nutzen? Die Wärme könnte man sinnvoll in Fernwärmenetze einspeisen oder Gebäude heizen. Gleichzeitig sollte energieeffiziente Hardware verwendet werden, um die laufenden Kosten zu senken.
- Verringerung menschlicher Fehler:
Aufgabe 2.2: Eigenschaften eines Hochleistungsrechners
Unsere Rechnersysteme basieren grob auf einer Balance zwischen Rechenwerk, Speicher und Verbindungsnetz. Wie setzen Sie die Schwerpunkte für ein HPC-System und für ein HTC-System?
Was waren nochmal Rechenwerk, Speicher und Verbindungsnetz, HPC und HTC?
Rechenwerk (ALU):
- Führt Berechnungen und logische Operationen durch.
- Zentral für die Leistung von High Performance Computing (HPC) Systemen.
Speicher:
- Besteht aus schnellem Cache, RAM und großem Hauptspeicher.
- Wichtig für die Datenverarbeitung und -speicherung in High Throughput Computing (HTC) Systemen.
Verbindungsnetz:
- Verbindet CPU, Speicher und andere Komponenten.
- Ermöglicht schnelle Datenübertragung in Rechenzentren.
Rechenzentren:
- Einrichtungen mit vielen Rechnern zur Datenverarbeitung und -speicherung.
HPC (High Performance Computing):
- Systeme für komplexe, rechenintensive Aufgaben wie wissenschaftliche Simulationen.
HTC (High Throughput Computing):
- Systeme, die viele Aufgaben gleichzeitig verarbeiten, ideal für große Datenmengen und Aufgabenvielfalt.
Zusammenfassung: Ein optimiertes Zusammenspiel von Rechenwerk, Speicher und Verbindungsnetz ist entscheidend für die Effizienz und Leistungsfähigkeit moderner Rechenzentren sowie spezialisierter HPC- und HTC-Systeme.
1. Grundidee der beiden Paradigmen
- HPC (High Performance Computing)
Fokus auf tightly-coupled, rechenintensive Aufgaben, bei denen viele Prozessoren gleichzeitig an einem großen Problem arbeiten (z.B. Simulationen, numerische Modelle). Die Parallele Kommunikation ist hier enorm wichtig, um Daten schnell und in großen Mengen zwischen den Knoten austauschen zu können. - HTC (High Throughput Computing)
Fokus auf loosely-coupled Aufgaben, bei denen viele unabhängige Jobs abgearbeitet werden. Man braucht vor allem ausreichend Rechenkapazität (Rechenwerk) – und zwar weniger auf jedem einzelnen Knoten, sondern verteilt über sehr viele Knoten (z.B. Grid-Computing, Cloud-Services für Data Mining). Die Kommunikation zwischen den Jobs ist minimal; sie sind in der Regel unabhängig voneinander und teilen sich nur selten Daten.
2. Schwerpunkte in der Systemarchitektur
2.1 HPC-Systeme
- Kommunikationsnetz / Interconnect
- Zentraler Faktor wegen des engen Datenaustauschs zwischen den parallelen Prozessen.
- Erfordert niedrige Latenz und hohe Bandbreite (z.B. InfiniBand, High-Speed Ethernet, proprietäre Netzwerke in Supercomputern).
- Speicher
- Ebenfalls sehr wichtig, aber vor allem die schnelle Anbindung (Speicherbandbreite), damit die Rechenwerke (CPUs/GPUs) nicht ausgebremst werden.
- Gemeinsame Speicher (Shared Memory) oder verteilte Speicherarchitekturen (Distributed Memory), häufig mit großen Cache-Hierarchien.
- Rechenwerk
- Sehr hohe FLOPS-Leistung (z.B. HPC-CPUs, GPUs, spezialisierte Beschleuniger).
- Wird häufig zusammen mit dem Netzwerk optimiert, da ohne gutes Kommunikationsnetz ein großer Teil der Rechenleistung brachliegen würde.
Typische Kennzahlen: FLOPS, Tasks/s, Netzwerk-Latenz, Speicherbandbreite.
2.2 HTC-Systeme
- Rechenwerk
- Fokus auf möglichst viele durchschnittliche Prozessoren/Knoten, um eine Vielzahl von Jobs unabhängig zu bearbeiten.
- Die Leistung pro Knoten muss nicht extrem sein, aber skalierbar (viele Knoten).
- Speicher
- Oft hohe Gesamtkapazität für große Datenmengen, aber die Zugriffszeit ist weniger kritisch, da die Jobs häufig entkoppelt sind.
- Benötigt wird vor allem Skalierbarkeit, um die wachsende Zahl an Aufgaben und Daten parallel bedienen zu können.
- Kommunikationsnetz
- Muss robust und ausfallsicher sein, aber nicht unbedingt extrem niedrige Latenz haben, da die Aufgaben nur gering miteinander interagieren.
- Standard-Ethernet-Netzwerke mit ausreichender Bandbreite genügen meist.
Typische Kennzahlen: Jobs pro Stunde/Tag/Monat, Durchsatz, Gesamt-Rechenzeit pro Job.
3. Gegenüberstellung HPC vs. HTC
| Aspekt | HPC (tightly-coupled) | HTC (loosely-coupled) |
|---|---|---|
| Ziel | Komplexe, rechenintensive Probleme in kurzer Zeit parallel lösen | Sehr viele unabhängige Aufgaben (Jobs) über einen längeren Zeitraum effizient abarbeiten |
| Kommunikationsnetz | Hauptaugenmerk: Niedrige Latenz, hohe Bandbreite (z.B. InfiniBand) | Standard-Netzwerkinfrastruktur, Hauptsache robust und skalierbar (Latenz eher sekundär) |
| Rechenwerk | Hohe FLOPS: CPUs, GPUs, Beschleuniger (Synergie mit dem schnellen Netz) | Hauptaugenmerk: Viele (ggf. normale) Prozessoren, Hauptsache durchsatzstark und in großer Anzahl |
| Speicher | Schneller Speicherzugriff (Bandwidth), ggf. hoch optimiert | Große Gesamtkapazität, gute Verteilung, meist weniger wichtig als Gesamt-Durchsatz |
| Typische Metriken | FLOPS, Tasks/s, Netzwerk- und Speicherbandbreite | Jobs/Monat oder -Jahr, Gesamtdurchsatz, Kosten pro Job |
| Anwendungsfälle | Wettermodelle, Simulationen (CFD, FE-Methoden), Wissenschaft, Supercomputer | Grid-Computing, Batch-Processing, Data Mining, Cloud-Services |
Im Abhängigkeitsdreieck dargestellt
Rechenwerk
/\
/ \
/ \
/ t\
/ p\
/ \
/ \
/ \
/________________\
Speicherwerk Kommunikationsnetzp → HPC t → HTC
Aufgabe 2.3: Linpack Benchmark
Ein Maßstab für die Performance eines Höchstleistungsrechners wird in GFlop/s angegeben.
1. Was genau sind GFlop/s?
Lösung
Gigaflops pro Sekunde (GFlop/s) sind eine Maßeinheit für die Rechenleistung eines Computers oder Prozessors. Sie gibt an, wie viele Milliarden Gleitkommaoperationen (Floating-Point Operations) ein Prozessor pro Sekunde ausführen kann. Diese Messgröße wird häufig verwendet, um die Leistungsfähigkeit von Prozessoren, insbesondere in wissenschaftlichen und technischen Anwendungen, zu bewerten. GFlop/s sind ein wichtiger Indikator für die Effizienz und Geschwindigkeit von Rechenoperationen bei numerischen Berechnungen.
Gigaflops pro Sekunde (GFlop/s) sind eine Maßeinheit für die Rechenleistung eines Computers oder Prozessors. Es wird die Anzahl an Gleitkommaoperationen pro Sekunde widergegeben, diese Einheit hat sich als Nachweis für die Leistung eines Prozessors etabliert
2. Warum ist dies unter Umständen kein objektives Maß? Gibt es ein besseres? (Die Grenzen von FLOPS als Maß für die Computerleistung)
Wie oben beschrieben, sind FLOPS “FLoating-point Operations Per Second”. Also eine mathematische Berechnung auf Gleitkommazahlenbasis. CPUs führen jedoch nicht nur Prozesse aus, die auf floating point mathematics basieren, sondern auch viele andere Operationen, wie logische Vergleiche, Ganzzahlberechnungen oder das Verwalten von Datenbewegungen. FLOPS berücksichtigen diese nicht und geben deshalb kein vollständiges Bild der tatsächlichen Leistung einer CPU.
Eine bessere Alternative sind praxisnahe Benchmarks wie SPECint oder SPECfp, die die Gesamtleistung eines Systems unter realistischen Bedingungen testen. Diese berücksichtigen zusätzlich Speicherzugriffe, Parallelität und die Effizienz verschiedener Operationen.
Bestimmen Sie den Linpack-Wert auf Ihrem Smartphone wie in der Vorlesung gezeigt.
3. Setzen Sie Ihr Resultat in GFlop/s in Bezug zur aktuellen Top500-Liste.
iPhone12,3-D421AP / 6 cores
- Problem size: 500
- Number of runs: 100
- Multithread mode: Aktiviert
- Run: #100
- Mflop/s: 5006.88
- Time: 0.1080
- Norm Res: 5.1700
- Precision: 2.22044605e-16
Max Mflop/s: 9402.84 ()
Avg Mflop/s: 5412.55
Der letzte Platz auf der Top 500 Liste ist:
| Rank | System | Cores | Rmax (PFlop/s) | Rpeak (PFlop/s) | Power (kW) |
|---|---|---|---|---|---|
| 500 | HSUper - Megware D50TNP, Xeon Platinum 8360Y 36C 2.4GHz, InfiniBand HDR100, MEGWARE Helmut-Schmidt-Universität/Universität der Bundeswehr Hamburg Germany | 41,832 | 2.13 | 3.21 | 395 |
Vergleich:
oder:
Mein Handy kommt nicht mal Ansatzweise an den schlechtesten Supercomputer in der aktuellen Liste dran. Der HSUper ist leistungsfähiger als mein Iphone
4. Gehen Sie die historisch schnellsten Hochleistungsrechner der Top500-Liste durch. Wäre Ihr Smartphone irgendwann so leistungsstark gewesen? Wenn ja, wäre es als Hochleistungsrechner einsetzbar gewesen?
Ja wäre es, mein Iphone hätte zwar niemals den ersten Platz belegen können, hätte aber bis knapp zum 11/1997 es in die Top500 geschafft auch wenn eher am Anfang im Mittelfeld und gegen Ende eher weiter unten. Mit dem vom oben berechneten Benchmark hätte mein Iphone also als Hochleistungsrechner bis knapp 11/1977 genutzt werden können.
Aufgabe 2.4: Ein Tag im Leben eines Grid-Jobs
Abbildung 1 zeigt schematisch „einen Tag im Leben eines Grid-Jobs“ (Auch wenn es sich hier um Grid-Jobs handelt, sind die Konzepte auch in Clouds wiederzufinden – allerdings sehr viel einfacher).
Um einen ersten Überblick über die Inhalte und Zusammenhänge im Grid und Cloud Computing zu erhalten, geben Sie bitte zu jeder der vier in Abbildung 1 angegebenen Sequenzen (Initialisierung, Input, Ausführung, Output) stichpunktartig an, welche Aufgaben Ihrer Meinung nach dort jeweils erfüllt werden müssen und welche Probleme dabei auftauchen können. Beachten Sie, dass die Wolken in Abbildung 1 reale Organisationen darstellen.
Ziel der Aufgabe ist nicht die vollständige Auflistung aller möglichen Aufgaben (was aufgrund von Überschneidungen und der Fülle der Funktionalitäten ohnehin nicht möglich wäre). Vielmehr soll sie Ihnen den Einstieg in das Themengebiet erleichtern. Dazu ist die Spezifikation der Open Grid Services Architecture (OGSA) (Link zur Quelle) eine gute Quelle für Ihre Recherche.
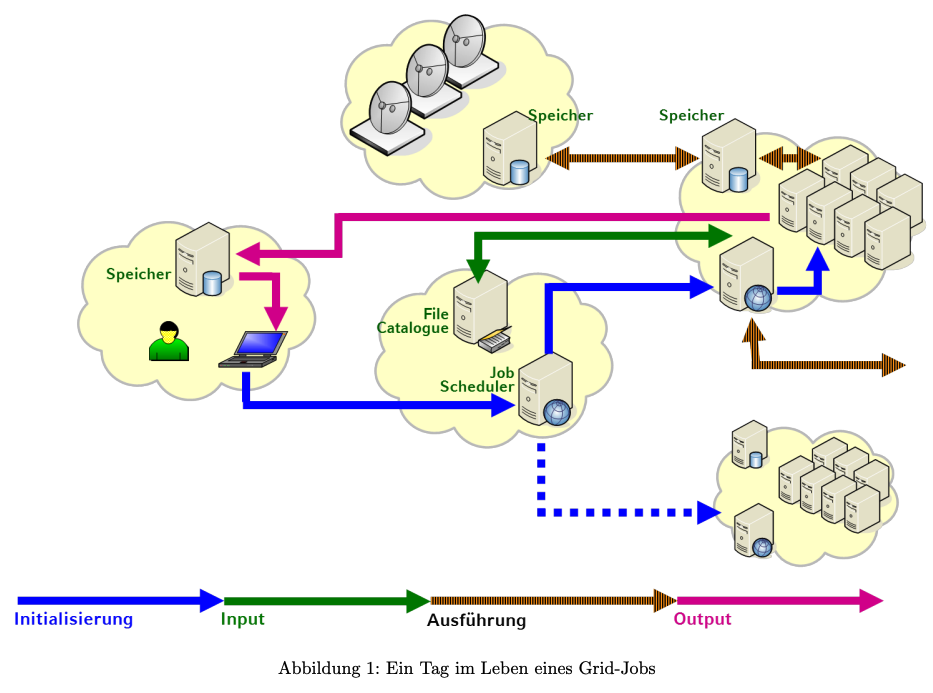
1. Initialisierung
Aufgaben:
- Job-Einreichung: Benutzer reicht den Grid-Job über eine Schnittstelle ein
- Authentifizierung: Überprüfung der Benutzerrechte
- Ressourcenplanung: Zuweisung von CPU, Speicher und weiteren Ressourcen
- Job-Scheduling: Platzierung des Jobs in der Warteschlange
Mögliche Probleme:
- Authentifizierungsfehler: Zugriff wird verweigert
- Ressourcenknappheit: Verzögerungen durch unzureichende Ressourcen
- Ineffizientes Scheduling: Längere Wartezeiten
2. Input
Aufgaben:
- Datenübertragung: Eingabedaten werden an die Grid-Knoten gesendet
- Datenvalidierung: Sicherstellung der Datenintegrität und -kompatibilität
- Datenverteilung: Aufteilung der Daten für parallele Verarbeitung
Mögliche Probleme:
- Netzwerkengpässe: Langsame Datenübertragung
- Datenfehler: Beschädigte oder unvollständige Daten
- Sicherheitsrisiken: Datenlecks während der Übertragung
3. Ausführung
Aufgaben:
- Prozessmanagement: Starten und Überwachen der Job-Prozesse
- Lastverteilung: Optimale Nutzung der verfügbaren Ressourcen
- Fehlerbehandlung: Umgang mit Laufzeitfehlern und Ausfällen
Mögliche Probleme:
- Hardware-Ausfälle: Unterbrechung der Job-Ausführung
- Software-Inkompatibilitäten: Fehler durch fehlende Abhängigkeiten
- Leistungsschwankungen: Unstabile Performance der Knoten
4. Output
Aufgaben:
- Ergebnissammlung: Zusammenführung der Ausgaben von allen Knoten
- Datenvalidierung: Überprüfung der Ergebnisqualität
- Rückgabe der Ergebnisse: Übermittlung an den Benutzer
- Ressourcenfreigabe: Freigabe der verwendeten Ressourcen
Mögliche Probleme:
- Datenkonsistenz: Fehlerhafte oder unvollständige Ergebnisse
- Speicherengpässe: Schwierigkeiten bei der Speicherung großer Ausgabedaten
- Zugriffsprobleme: Benutzer erhält die Ergebnisse nicht rechtzeitig