(a) Interpretieren Sie den Koeffizienten Wassermenge.
(b) Berechnen Sie die erwartete Überlebensdauer auf dem Standort Tisch bei einer Wassermenge von 2000 mL/Tag.
(c) Bewerten Sie die Interpretierbarkeit der erwarteten Überlebensdauer auf dem Standort Tisch bei einer Wassermenge von 2000 mL/Tag.
(d) Interpretieren Sie den Effekt der Wassermenge auf dem Standort Tisch von Modell 1d.
(e) Severin führt nun folgenden R-Code aus.
(f) Ein Diagnostik-Plot könnte wie folgt aussehen.
(g) Im Vergleich zu Modell 1a ist in Modell 1g nun die Variable Wassermenge_fakt statt Wassermenge verwendet worden. Was wurde inhaltlich getan?
(h) Interpretieren Sie die Regressionskoeffizienten zur Variable Wassermenge_fakt in Modell 1g.
(i) Wie viele Regressionskoeffizienten hat das Modell 1i?
(j) Der Effektplot für Modell 1i sieht wie folgt aus.
Aufgabe 2
(a) Die Assoziation zwischen Wachstum und Düngermittelsorte soll mit Hilfe eines linearen Regressionsmodells geschätzt werden.
(b) Stellen Sie sich nun vor, dass Sie anstatt der Referenzkodierung eine Effektkodierung wählen.
(c) Nehmen Sie an, dass Sie nun das Modell beschrieben in Aufgabe 2b) in R gefittet haben.
(d) Es wird angenommen, dass die Fehler ϵi unabhängig und identisch verteilt sind.
(e) Beschreiben Sie kurz, wann eine gewichtete KQ-Schätzung einer ungewichteten KQ-Schätzung vorzuziehen wäre.
(f) Erläutern Sie, anhand einer der oben aufgeführten Modelle, wie eine Transformation des Modells in einer gewichteten KQ-Schätzung aussehen würde.
Aufgabe 3
(a) Worauf beziehen sich die Laufindizes i und t?
(b) Welche Variablen sind zeitabhängig? Welche sind zeitkonstant?
(c) Sie sehen eine Visualisierung des gpa einer Auswahl von SchülerInnen in Abhängigkeit des Zeitpunkts.
(d) Nehmen Sie an, Sie würden für die in der Angabe genannte Fragestellung ein lineares Regressionsmodell benutzen.
(e) Welche Annahme des linearen Regressionsmodells wird durch die longitudinale Struktur des Datensatzes verletzt?
(f) Nennen Sie zwei Ansätze, mit Mehrfachmessungen dieser Art umzugehen, sodass die oben genannte Annahme nicht verletzt wird.
(g) Es soll nun ein lineares gemischtes Modell mit zufälligem Intercept geschätzt werden.
(h) Stellen Sie nun die Modellgleichung des linearen gemischten Modells auf und nennen Sie die Annahmen des Modells.
(i) Das eben definierte gemischte lineare Modell wurde nun geschätzt. Berechnen und interpretieren Sie den Interclass Correlation Coefficient (ICC).
(j) Betrachten Sie nun folgendes Streudiagramm von Fitted Values (x-Achse) vs. Residuals (y-Achse).
Aufgabe 4
(a) Interpretieren Sie für folgendes Modell (Modell 4a) die geschätzten Koeffizienten von dem Impfstatus.
(b) Berechnen Sie für die den Koeffizienten von Alt75-79 das Konfidenzintervall zum Niveau α=0.05.
(c) Für den Koeffizienten des Impfstatus (impfstungeimpft) ist der Wert 0 nicht im 95%-Konfidenzintervall enthalten.
(d) Geben Sie für Modell 4a die Struktur- und Verteilungsannahme an.
(e) Nun wird ein weiteres Modell (Modell 4e) geschätzt.
(f) Welche zusätzliche Fragestellung wird in Modell 4e, im Vergleich zu Modell 4a, bearbeitet?
(g) Vergleichen Sie die Ergebnisse von Modell 4a und Modell 4e inhaltlich im Hinblick auf Alters- und Impfstatus-Effekte.
(h) Die zugehörige ANOVA zu Modell 4e ist.
(i) Welches Modell ist zu bevorzugen? Begründen Sie kurz.
Aufgabe 1
Aufgabenstellung
Statistikstudent Severin sterben ständig seine Basilikumpflanzen. Seit Jahren schaut er, wie lange es dauert bis seine Pflanze stirbt und verändert dabei die Variablen Wassermenge und Standort.
Variable
Ausprägungen
Wassermenge
50, 100, 150 [mL/Tag]
Standort
Fensterbank, Tisch
Ueberlebenszeit
7 - 45 [Tage]
Er rechnet nun folgendes Modell 1a in R, um die idealen Bedingungen für ein möglichst langes Überleben des Basilikums zu finden.
Modell 1a
(a) Interpretieren Sie den Koeffizienten Wassermenge.
Der Koeffizient für Wassermenge beträgt 0.10000
Für jeden zusätzlichen Tagml Wasser, die der Basilikumspflanze gegeben wird, steigt die erwartete Überlebenszeit der Pflanze um 0.10000 Tage
(b) Berechnen Sie die erwartete Überlebensdauer auf dem Standort Tisch bei einer Wassermenge von 2000 mL/Tag.
→ Überlebensdauer der Pflanze auf dem Standort Tisch beträgt 207 Tage
(c) Bewerten Sie die Interpretierbarkeit der erwarteten Überlebensdauer auf dem Standort Tisch bei einer Wassermenge von 2000 mL/Tag.
Die erwartete Überlebensdauer von 207 Tagen bei einer Wassermenge von 2000 mL/Tag ist schwer zu interpretieren. Diese Menge liegt weit außerhalb des beobachteten Bereichs (50-150 mL/Tag), und die Überlebenszeit in den Daten beträgt nur 7-45 Tage. Eine so hohe Wassermenge könnte zu Überwässerung führen, was das lineare Modell nicht berücksichtigt. Daher ist die Schätzung unzuverlässig und biologisch nicht plausibel. Das Modell liefert nur innerhalb der beobachteten Datenbereich und somit Überlebenszeiten verlässliche Vorhersagen.
Aufgabenstellung
Im nächsten Schritt möchte Severin herausfinden, ob es eine Interaktion zwischen der Wassermenge und dem Standort gibt und rechnet dazu Modell 1d.
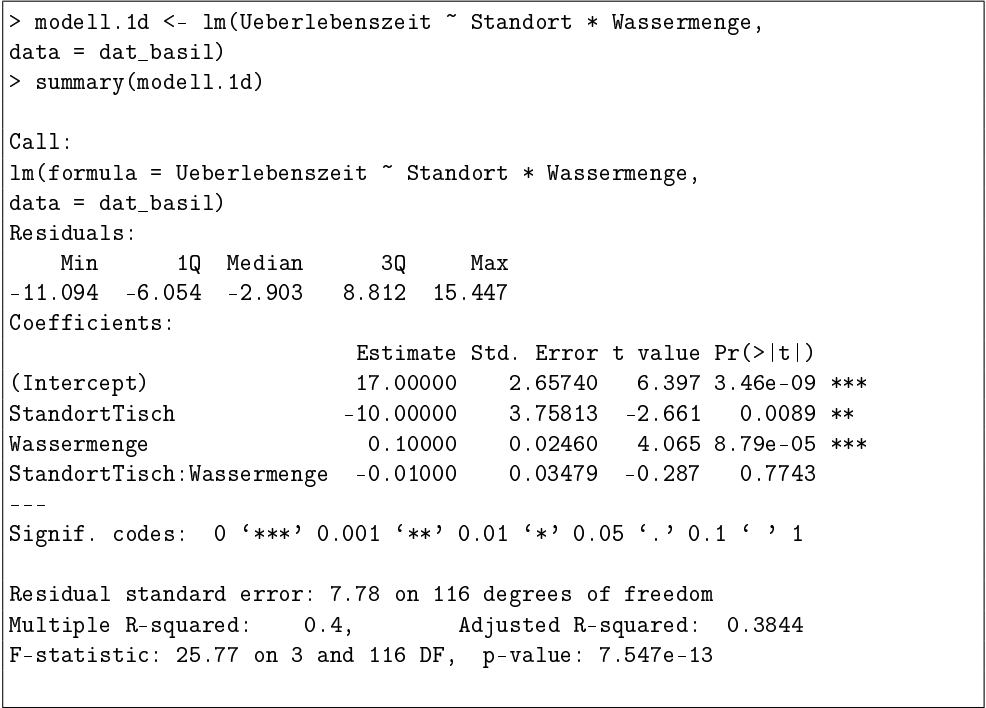
Modell 1d
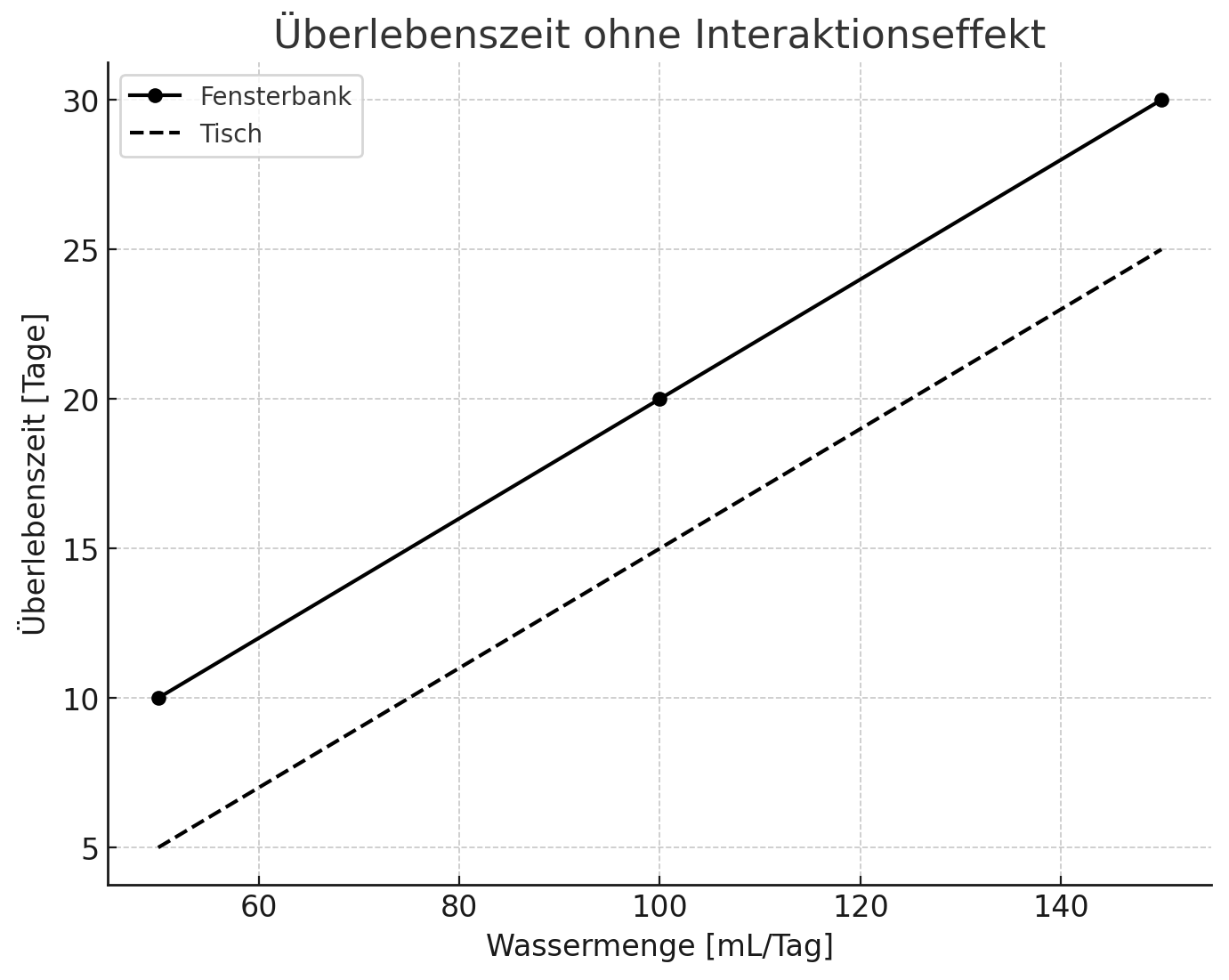
(d) Interpretieren Sie den Effekt der Wassermenge auf dem Standort Tisch von Modell 1d.
β0 (Intercept): 17.00000
β1 (StandortTisch): -10.00000
β2 (Wassermenge): 0.10000
β3 (StandortTisch:Wassermenge): -0.01000
Der Effekt der Wassermenge auf dem Standort Tisch wird durch die Summe der Koeffizienten β2 und β3 dargestellt:
Effekt der Wassermenge=β2+β3
Setzen wir die Werte ein:
Effekt der Wassermenge=0.10000+(−0.01000)Effekt der Wassermenge=0.09000
Das bedeutet, dass für jede zusätzliche Einheit der Wassermenge (1 mL/Tag) die Überlebenszeit der Basilikumpflanzen am Standort Tisch um 0.09 Tage zunimmt.
Dieser Effekt ist jedoch etwas geringer als am anderen Standort, wo der Effekt 0.1 Tage pro zusätzlichem mL/Tag beträgt. Das negative Vorzeichen des Interaktionsterms (β3=−0.01000) deutet darauf hin, dass der positive Effekt der Wassermenge auf die Überlebenszeit am Standort Tisch schwächer ist als an anderen Standorten.
(e) Severin führt nun folgenden R-Code aus.
> anova(modell1.1a, modell1.1d)Analysis of Variance TableModel 1: Ueberlebenszeit ~ Standort + WassermengeModel 2: Ueberlebenszeit ~ Standort * Wassermenge Res.Df RSS Df Sum of Sq F Pr(>F)1 117 7021.52 116 7021.4 1 0.054493 9e-04 0.9761
i) Geben Sie die zugehörige Nullhypothese an.
→ ANOVA-Test erstes Argument ist H0 in diesem Fall modell1.1a, was unten Model 1: Ueberlebenszeit ~ Standort + Wassermenge
H0: Es gibt keine Interaktion zwischen der Wassermenge und dem Standort auf die Überlebenszeit der Basilikumpflanzen.
Das bedeutet, dass die zusätzliche Komplexität des Modells, das die Interaktion zwischen Wassermenge und Standort berücksichtigt, die Modellanpassung nicht signifikant verbessert im Vergleich zu einem Modell ohne diese Interaktion.
ii) Kann die Nullhypothese zum Signifikanzniveau von 5% abgelehnt werden? Begründen Sie kurz.
Nein, die Nullhypothese kann zum Signifikanzniveau von 5% nicht abgelehnt werden.
Begründung: Der p-Wert für den ANOVA-Test beträgt 0.9761, was deutlich größer als das Signifikanzniveau von 0.05 ist. Ein p-Wert größer als 0.05 bedeutet, dass es keine ausreichenden Beweise gibt, um die Nullhypothese abzulehnen. Somit gibt es keinen signifikanten Unterschied zwischen dem Modell mit und dem Modell ohne die Interaktion zwischen Wassermenge und Standort.
iii) Welche Schlussfolgerung ziehen Sie daraus?
Die Schlussfolgerung daraus ist, dass die Interaktion zwischen der Wassermenge und dem Standort keinen signifikanten Einfluss auf die Überlebenszeit der Basilikumpflanzen hat. Das Modell ohne Interaktion (Modell 1.1a) erklärt die Überlebenszeit genauso gut wie das Modell mit Interaktion (Modell 1.1d). Daher kann die zusätzliche Komplexität durch die Interaktion nicht gerechtfertigt werden, und wir sollten das einfachere Modell ohne Interaktion bevorzugen.
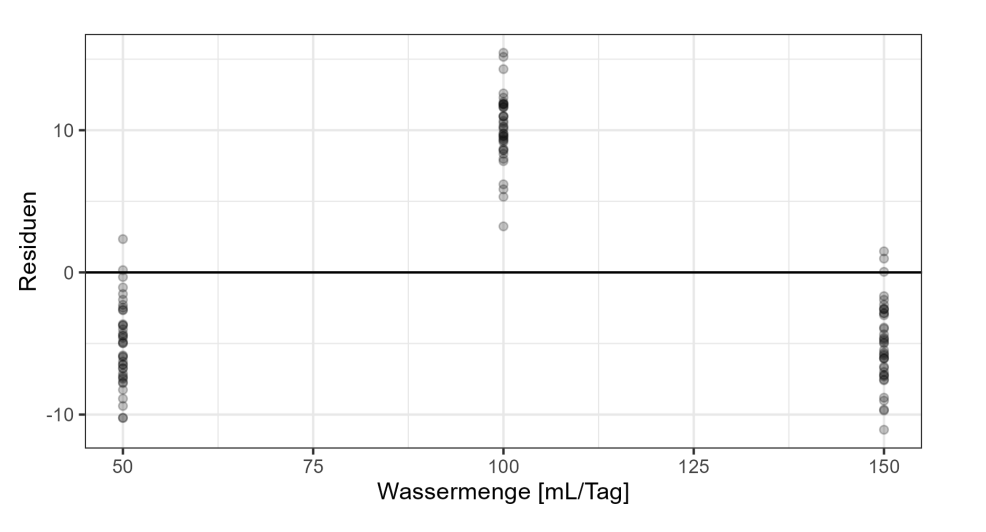
(f) Ein Diagnostik-Plot könnte wie folgt aussehen.
i) Geben Sie an, welche Modellannahme verletzt sein könnte und nennen Sie KURZ die Begründung, warum Sie dies vermuten.
Eugens Lösung
Annahme: Die Überlebenszeit hängt lineas von der Wassermenge ab.
Die Annahme scheint falsch zu sein, da die echten Werte systematisch über oder unter
unserer Schätzung liegen.
Die Modellannahme, die verletzt sein könnte, ist die Annahme der Homoskedastizität (konstante Varianz der Residuen).
Varianz der Residuen (= Abweichung vom vorhergesagten Wert) ist nicht konstant und weicht sehr stark ab, zum Beispiel bei 50 schwant es von -10 bis nahezu +3
Dies verletzt die Homoskedaszität
Begründung: Im Diagnostik-Plot zeigt sich, dass die Streuung der Residuen für verschiedene Wassermengen unterschiedlich ist. Insbesondere bei 100 mL/Tag scheinen die Residuen eine größere Streuung zu haben als bei 50 mL/Tag oder 150 mL/Tag. Dies deutet darauf hin, dass die Varianz der Fehlerterme nicht konstant ist, was eine Verletzung der Homoskedastizitätsannahme bedeutet.
ii) Geben Sie eine Lösungsmöglichkeit an.
Eugens Lösung
Wassermenge als kategorialle Größe ins Modell
aufnehmen, anstatt als numerische Größe.
Eine Lösungsmöglichkeit besteht darin, das Modell anzupassen, um die Annahmeverletzungen zu korrigieren:
Homoskedastizität: Verwenden Sie robuste Standardfehler oder transformieren Sie die abhängige Variable (z.B. log-Transformation).
Linearität: Fügen Sie nichtlineare Terme (z.B. quadratische Terme) hinzu.
Normalverteilung der Residuen: Transformieren Sie die abhängige Variable oder verwenden Sie robuste Regressionstechniken.
Beispiel für log-Transformation:
modell1.1a_log <- lm(log(Ueberlebenszeit) ~ Standort + Wassermenge, data = dat_basil)summary(modell1.1a_log)
Aufgabenstellung
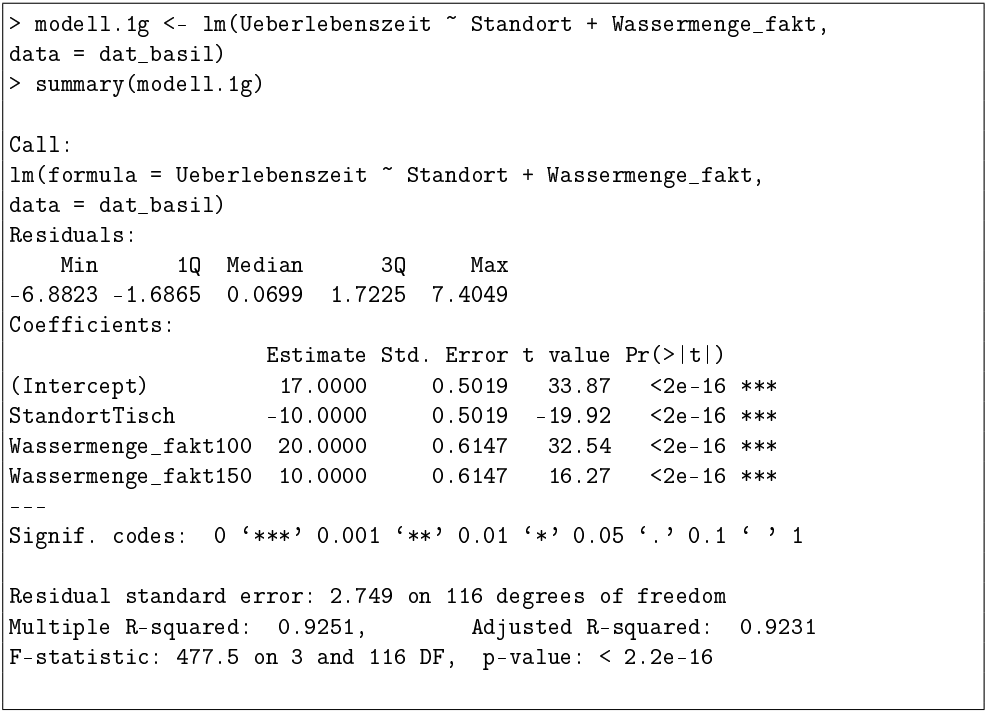
Modell 1g
(g) Im Vergleich zu Modell 1a ist in Modell 1g nun die Variable Wassermenge_fakt statt Wassermenge verwendet worden. Was wurde inhaltlich getan? Hinweis: Severin hat nur die Wassermenge 50, 100 und 150 mL/Tag ausprobiert.
Eugens Lösung
Die Variable Wassermenge wurde dirkretisiert und in eine Rategorielle Variable mit den Werten 50 ml/Tag , 100 ml/ Tag und 150 ml/ag unterteilt. Herbei ist 50mL/Tag der Referenzwert.
In Modell 1g wurde die kontinuierliche Variable “Wassermenge” durch die faktorielle Variable “Wassermenge_fakt” ersetzt. Dies bedeutet, dass die Wassermengen von 50, 100 und 150 mL/Tag als separate Kategorien (Faktoren) behandelt wurden, anstatt als kontinuierliche Werte.
Inhaltliche Veränderung
Wassermenge_fakt100: Repräsentiert den Effekt der Wassermenge von 100 mL/Tag im Vergleich zur Referenzkategorie (50 mL/Tag).
Wassermenge_fakt150: Repräsentiert den Effekt der Wassermenge von 150 mL/Tag im Vergleich zur Referenzkategorie (50 mL/Tag).
Ergebnis
Die Koeffizienten zeigen, dass im Vergleich zu 50 mL/Tag:
100 mL/Tag die Überlebenszeit um 20 Tage erhöht.
150 mL/Tag die Überlebenszeit um 10 Tage weiter erhöht (also insgesamt um 30 Tage im Vergleich zu 50 mL/Tag).
Dies deutet darauf hin, dass höhere Wassermengen signifikant die Überlebenszeit der Basilikumpflanzen verlängern.
(h) Interpretieren Sie die Regressionskoeffizienten zur Variable Wassermenge_fakt in Modell 1g.
Eugens Lösung
Wenn die Wassermenge S0mL/Tag beträgt und die Pfanze auf dem Fensterbrett steht, dann beträgt die Duschschnittliche Überlebenszeit 17 Tage. Wenn die Wassermenge von 50 mL tag auf 100 mL/Tag Steigt, dann steigt die überlebenszeit ceteris paribus im Durchschnitt un 20 Tage. Wenn die Wascermenge von 50mL/Tag auf 150 mL /Tag steigt, dann Steigt die Überlebenszeit ceteris paribus im Durchschnitt um 10 Tage.
Wassermenge_fakt100 (20.0000):
Pflanzen, die 100 mL/Tag Wasser bekommen, leben im Durchschnitt 20 Tage länger als Pflanzen, die 50 mL/Tag Wasser bekommen.
Wassermenge_fakt150 (10.0000):
Pflanzen, die 150 mL/Tag Wasser bekommen, leben im Durchschnitt 10 Tage länger als Pflanzen, die 50 mL/Tag Wasser bekommen.
Zusammengefasst zeigt eine Erhöhung der Wassermenge auf 100 mL/Tag eine größere Verlängerung der Überlebenszeit (20 Tage) im Vergleich zu einer Erhöhung auf 150 mL/Tag (10 Tage).
Aufgabenstellung
Im letzten Schritt rechnet Severin noch ein Modell Modell 1i.
Modell 1i
modell1.1i <- lm(Ueberlebenszeit ~ Standort * Wassermenge_fakt, data = dat_basil)summary(modell1.1i)
(i) Wie viele Regressionskoeffizienten hat das Modell 1i?
Modell 1i berücksichtigt die Interaktion zwischen dem Standort und der faktorisierten Wassermenge. Um die Anzahl der Regressionskoeffizienten in Modell 1i zu bestimmen, schauen wir uns die Komponenten des Modells an:
Das Modell lautet:
U¨berlebenszeit∼Standort∗Wassermenge_fakt
Das bedeutet, dass wir folgende Terme haben:
Intercept (Basislevel für Standort und Wassermenge)
Standort (Ein Effekt: Tisch, da Fensterbank die Referenz ist)
Wassermenge_fakt (Zwei Effekte: 100 mL/Tag und 150 mL/Tag, da 50 mL/Tag die Referenz ist)
Modell 1i hat insgesamt 6 Regressionskoeffizienten.
Erklärung Interaktionsterms
Interaktionsterms
Ein Interaktionsterm im Regressionsmodell zeigt, wie zwei Variablen zusammen die Zielvariable beeinflussen. In deinem Modell berücksichtigt der Interaktionsterm, wie der Standort (Tisch oder Fensterbank) und die Wassermenge (50 mL/Tag, 100 mL/Tag, 150 mL/Tag) zusammen die Überlebenszeit beeinflussen.
Beispiel:
Ohne Interaktion: Der Effekt des Standorts und der Wassermenge werden getrennt betrachtet.
Mit Interaktion: Der Effekt des Standorts kann je nach Wassermenge unterschiedlich sein und umgekehrt.
Die Interaktionsterms β4 und β5 zeigen die zusätzliche Wirkung, wenn beide Faktoren kombiniert werden.
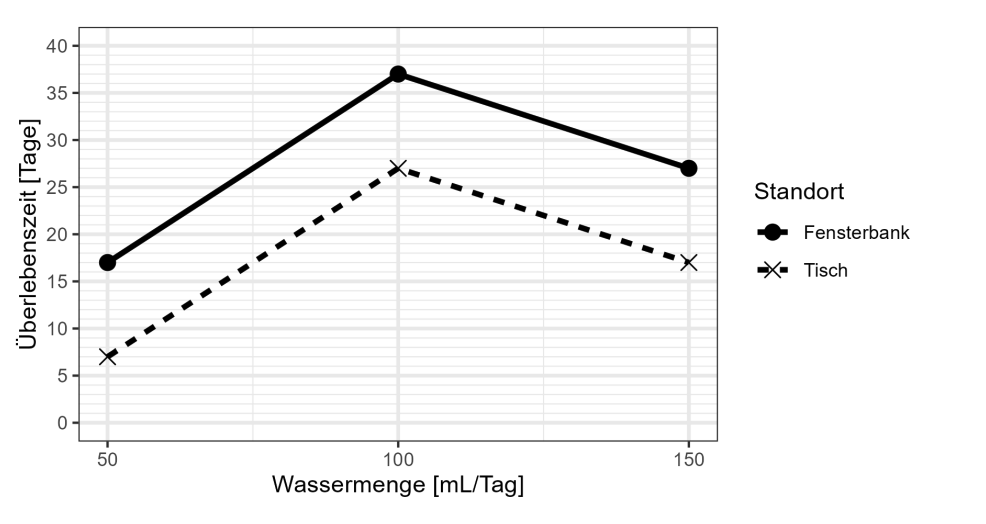
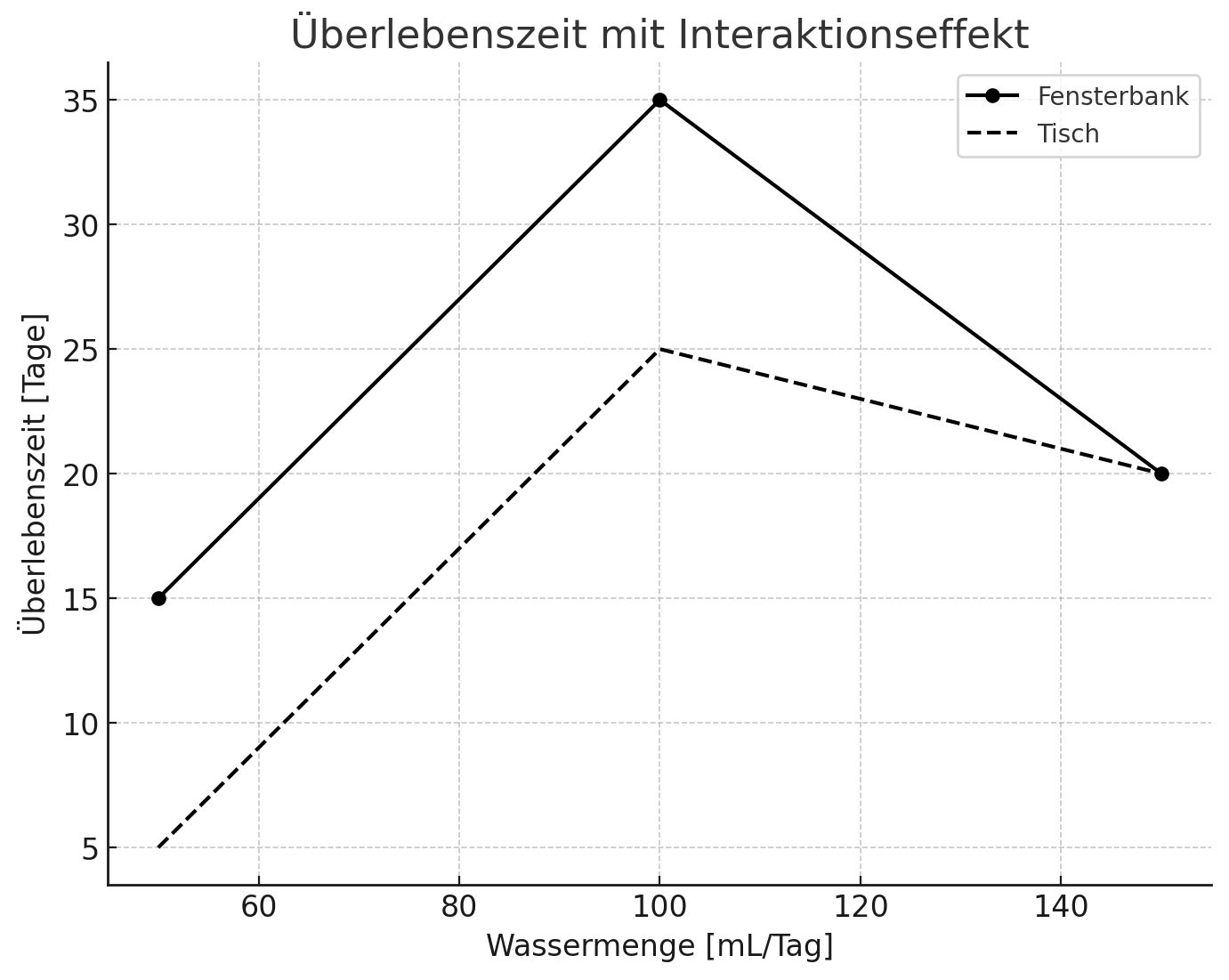
(j) Der Effektplot für Modell 1i sieht wie folgt aus:
Begründen Sie anhand der Grafik, ob es Indizien für einen Interaktionseffekt gibt und begründen Sie kurz.
Eugens Lösung
Es gibt keinen Hinweis auf Interaktionseffekte, da der Verlauf der Effektkurve für beide Standorte gleich ist und sich fast nur um einen konstanten Wert unterscheidet, d.h., die Linien verlaufen (fast) parallel.
Ein Interaktionseffekt tritt auf, wenn die Wirkung einer unabhängigen Variable auf die abhängige Variable von der Ausprägung einer anderen unabhängigen Variable abhängt. Mit anderen Worten, die gleichzeitige Wirkung zweier Variablen auf das Ergebnis unterscheidet sich von der Summe ihrer individuellen Wirkungen.
Ein Interaktionseffekt bedeutet, dass die Wirkung einer Sache auf ein Ergebnis davon abhängt, was mit einer anderen Sache passiert. Zum Beispiel, wie gut ein Medikament wirkt, könnte davon abhängen, wie viel Sport jemand treibt.
(Bsp ohne Interaktionseffekt)
(Bsp mit Interaktionseffekt)
Aufgabe 2
Aufgabenstellung
Nehmen Sie an, dass Sie die Assoziation zwischen drei Düngersorten und dem Wachstum (in cm) einer Staudenpflanzensorte zwischen der ersten und vierten Woche nach Keimung analysieren möchten.
Wir beobachten insgesamt 300 Samen in unserer Studie. 75 Samen werden mit dem ersten Dünger gedüngt (Treatment 1), 75 Samen werden mit dem zweiten Dünger gedüngt (Treatment 2), 75 Samen werden mit dem dritten Dünger gedüngt (Treatment 3) und 75 Samen werden als Kontrolle ohne Behandlung beobachtet.
(a) Die Assoziation zwischen Wachstum und Düngermittelsorte soll mit Hilfe eines linearen Regressionsmodells geschätzt werden. Wir nehmen an, dass die Düngermittelsorte mit einer Referenzkodierung in das Modell aufgenommen wird. Schreiben Sie die Modellgleichung aus. Sie dürfen in diesem Fall die Verteilungsannahmen auslassen. Definieren Sie die Ausprägungen der Kovariablen.
Eugens Lösung
Um die Assoziation zwischen Wachstum und Düngemittelsorte mit einem linearen Regressionsmodell zu schätzen, verwenden wir die Referenzkodierung. Die Kontrollgruppe (ohne Dünger) dient als Referenz.
Die Kontrollgruppe (ohne Dünger) ist durch den Achsenabschnitt β0 repräsentiert.
Das i in der Modellgleichung steht für die Beobachtungsnummer oder den einzelnen Samen in der Studie. Es zeigt an, dass jede Variable für jede einzelne Beobachtung (jedes i) gemessen wird. Es bedeutet also:
Wachstumi: Das Wachstum des i-ten Samens. (Bis 300)
ϵi: Der Fehlerterm für den i-ten Samen.
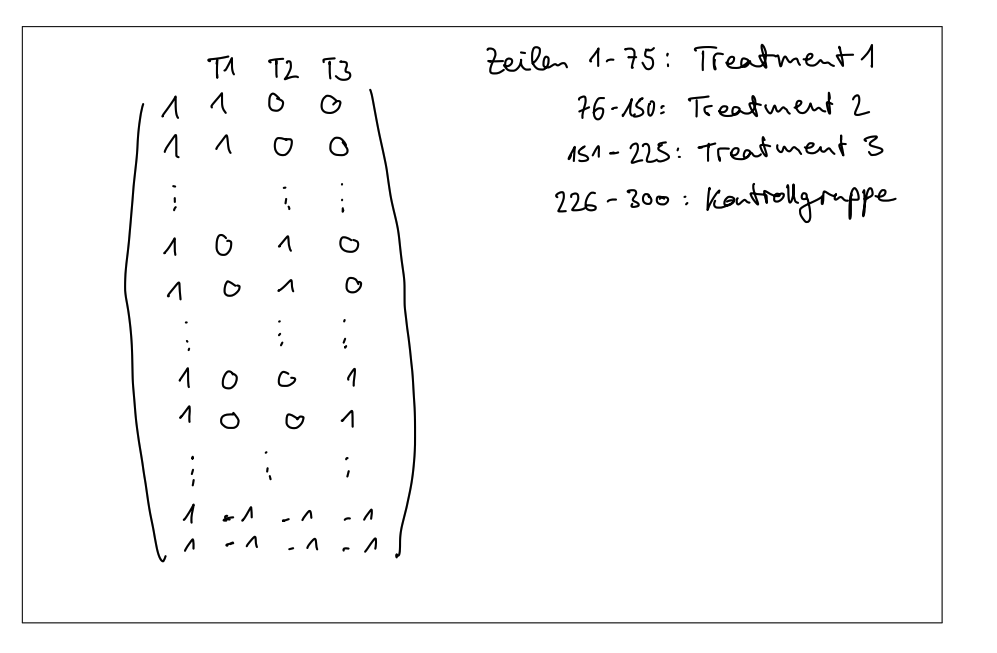
(b) Stellen Sie sich nun vor, dass Sie anstatt der Referenzkodierung eine Effektkodierung wählen. Skizzieren Sie hierfür eine dementsprechende Designmatrix. Geben Sie an welche Zeilen und welche Spalten welchem Dünger entsprechen. (Hinweis: Sie müssen NICHT 300 Zeilen ausschreiben. Kürzen Sie die Skizze Ihrer Designmatrix so viel wie möglich.)
Eugens Lösung
Ich glaube ich habe den Intercept vergessen
(c) Nehmen Sie an, dass Sie nun das Modell beschrieben in Aufgabe 2b) in R gefittet haben und dass Sie nun den folgenden Output bekommen.
Modell 2c
Call:lm(formula = y ~ Treatment, data = Xdata, contrasts= list(Treatment = "contr.sum"))Coefficients: (Intercept) Treatment1 Treatment2 Treatment3 5.7524 0.2886 3.1414 -2.7460
Hier beschreibt XData den oben beschriebenen Datensatz. “y” ist hier die Responsevariable, die für das Wachstum steht, und die Treatmentvariable steht für die jeweilige Behandlung der Pflanzen.
i) Nutzen Sie den Output des Modells 2c, um für alle drei Düngersorten jeweils das durchschnittliche Wachstum der Pflanzen per Hand zu berechnen.
Eugens Lösung
Treatment 1: 5.7524+0.2886=6.041
Treatment 2: 5.7524+3.1414 =8.89
Treatment 3: 5.7524-2.7460=3.0064
Intercept (Gesamtmittelwert):5.7524
Treatment 1:0.2886
Treatment 2:3.1414
Treatment 3:−2.7460
Berechnungen:
Durchschnittliches Wachstum für Treatment 1:
5.7524+0.2886=6.0410
Durchschnittliches Wachstum für Treatment 2:
5.7524+3.1414=8.8938
Durchschnittliches Wachstum für Treatment 3:
5.7524−2.7460=3.0064
Ergebnisse:
Treatment 1: 6.0410 cm
Treatment 2: 8.8938 cm
Treatment 3: 3.0064 cm
ii) Nehmen Sie an, dass Sie mit Hilfe eines F-Tests testen möchten, ob mindestens einer der Düngervarianten einen signifikanten Wachstumsunterschied zur Kontrollgruppe aufweist. Stellen Sie dafür die passenden Hypothesen und Test-Statistik auf. (Sie müssen den Test hier nicht durchführen.)
Eugens Lösung
Hypothesen für den F-Test
Nullhypothese (H0): Alle Düngervarianten haben keinen signifikanten Effekt auf das Wachstum im Vergleich zur Kontrollgruppe.
H0:β1=β2=β3=0
Alternativhypothese (HA): Mindestens eine Düngervariante hat einen signifikanten Effekt auf das Wachstum im Vergleich zur Kontrollgruppe.
HA:Mindestens eineβi(β1,β2,β3)ist nicht null
Test-Statistik
Die Test-Statistik für den F-Test ist wie folgt definiert:
F=Residual Sum of Squares (RSS) / (Gesamtanzahl der Beobachtungen - Anzahl der Regressoren - 1)Regressions-Sum of Squares (RSS) / Anzahl der Regressoren
(Regressions-Sum of Squares (RSS) / Anzahl der Regressoren)F = ----------------------------------------------------------------------- (Residual Sum of Squares (RSS) / (Gesamtanzahl der Beobachtungen - Anzahl der Regressoren - 1))
Dabei:
Regressions-Sum of Squares (RSS): Summe der Quadrate der Differenzen zwischen den vorhergesagten Werten und dem Gesamtmittelwert.
Residual Sum of Squares (RSS): Summe der Quadrate der Residuen, also der Differenzen zwischen den beobachteten Werten und den vorhergesagten Werten.
Berechnung der F-Statistik
Regressions-Sum of Squares (RSS):
RSS=∑(y^i−yˉ)2
Residual Sum of Squares (RSS):
RSS=∑(yi−y^i)2
F-Statistik:
F=n−k−1RSSReskRSSReg=MSEMSM
k : Anzahl der Regressoren (hier 3: β1, β2, β3)
n: Gesamtanzahl der Beobachtungen
Der F-Test vergleicht die Varianz, die durch das Modell erklärt wird, mit der Varianz, die durch die Residuen erklärt wird. Wenn der berechnete F-Wert größer als der kritische F-Wert aus der F-Verteilung ist, lehnen wir die Nullhypothese ab und schließen, dass mindestens eine Düngervariante einen signifikanten Effekt auf das Wachstum hat.
iii) Im folgenden sehen Sie, dass eine ANOVA in R genutzt wurde, um einen F-Test durchzuführen. Hier fehlen jedoch noch vier Felder; hier mit “a?”, “b?”, “c?” und “d?” gekennzeichnet. Vervollständigen Sie den Output. (Hinweis: Geben Sie bei Ihrer Antwort klar an, welches Feld Sie jeweils vervollständigen.)
Analysis of Variance TableResponse: y Df Sum Sq Mean Sq F value Pr(>F)Treatment a? b? d? 726.75 < 2.2e-16 ***Residuals 296 c? 0.62---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
F=MeanSqResidualsMeanSqTreatment
a:
Df = Anzahl der Freiheitsgrade → Anzahl der Treatments - 1 = 4
a = 4
b
SumSqResiduals = MeanSqResiduals⋅DfResiduals
SumSqResiduals = 0.62 ⋅ 296
b = 183.52
c
MeanSqTreatment = F⋅MeanSqResiduals
MeanSqTreatment = 726.75⋅0.62
c = 450.585
d
SumSqTreatment = MeanSqTreatment⋅DfTreatment
SumSqTreatment = 450.585⋅3
d = 1351.755
iv) Nutzen Sie Ihre Antwort aus der vorherigen Frage, um das adjustierte R2 für das Modell auszurechnen. Als Ersatzlösung dürfen Sie stattdessen auch 1500 als Streuung des Models annehmen und 200 als Residualstreuung.
Eugens Lösung
v) Diskutieren Sie kurz, ob in dieser Aufgabe ein R2 oder ein adjustiertes R2 als Bestimmtheitsmaß zu bevorzugen wäre. (Hinweis: Wir suchen nach jeweils einem Argument für beide Bestimmtheitsmaße.)
Eugens Lösung
1. Argument fürR2:
Einfachheit und Verständlichkeit:R2 ist einfach zu berechnen und zu interpretieren. Es gibt den Anteil der Variation der abhängigen Variablen an, der durch das Regressionsmodell erklärt wird. Wenn es darum geht, den allgemeinen Erklärungsgrad des Modells in einem ersten Schritt zu vermitteln, bietet R2 eine klare und verständliche Metrik.
2. Argument für den adjustiertenR2:
Berücksichtigung der Modellkomplexität: Der adjustierteR2 passtR2 an die Anzahl der Prädiktoren im Modell an. Er bestraft die Hinzufügung zusätzlicher Prädiktoren, die das Modell möglicherweise nicht signifikant verbessern, und verhindert somit eine Überbewertung der Modellgüte bei der Einführung unnötiger Variablen. Dies ist besonders wichtig, wenn man mehrere Modelle vergleicht oder eine Modellevaluation vornimmt, um Überanpassung zu vermeiden.
In der Praxis wäre der adjustierteR2 oft zu bevorzugen, insbesondere wenn das Modell viele Prädiktoren enthält oder wenn man Modelle vergleichen möchte, da er eine realistischere Einschätzung der Modellgüte bietet.
(d) Es wird angenommen, dass die Fehler ϵi unabhängig und identisch verteilt sind. Welche asymptotischen Eigenschaften besitzt die KQ-Schätzung? Wann werden diese benötigt?
Eugens Lösung
Die KQ-Schätzung (Kleinste-Quadrate-Schätzung) hat unter der Annahme, dass die Fehler Ei unabhängig und identisch verteilt sind, folgende asymptotische Eigenschaften:
Konsistenz: Die Schätzung konvergiert mit wachsendem Stichprobenumfang gegen den wahren Parameterwert.
Asymptotische Normalität: Die Verteilung der Schätzfehler wird normalverteilt, wenn die Stichprobe groß genug ist.
asymptotische Unverzerrheit: KQ-Schätzer sind im Durchschnitt gleich den wahren Parametern bei großen Stichproben
Benötigt bei:
Großen Stichproben
Hypothesentests
Erstellung von Konfidenzintervallen
(e) Beschreiben Sie kurz, wann eine gewichtete KQ-Schätzung einer ungewichteten KQ-Schätzung vorzuziehen wäre.
Eugens Lösung
Ungewichtete KQ-Schätzung
Was sie macht: Die ungewichtete KQ-Schätzung (Kleinste-Quadrate-Schätzung) minimiert die Summe der quadrierten Residuen (Differenzen zwischen beobachteten und geschätzten Werten). Sie geht davon aus, dass alle Fehlerterme die gleiche Varianz und keine systematischen Unterschiede aufweisen.
Wofür sie da ist: Verwendet, wenn alle Beobachtungen als gleich zuverlässig angenommen werden; Standardmethode bei homoskedastischen Fehlern.
Gewichtete KQ-Schätzung
Was sie macht: Die gewichtete KQ-Schätzung berücksichtigt unterschiedliche Varianzen der Fehlerterme, indem sie den Beobachtungen unterschiedliche Gewichte zuweist. Die Schätzung minimiert die gewichtete Summe der quadrierten Residuen, wobei präzisere Beobachtungen (mit geringeren Fehlern) mehr Gewicht erhalten.
Wofür sie da ist: Verwendet bei Heteroskedastizität oder unterschiedlichen Präzisionen der Beobachtungen, um genauere Schätzungen zu erhalten.
Lösung
Eine gewichtete KQ-Schätzung ist der ungewichteten KQ-Schätzung vorzuziehen, wenn:
Heteroskedastizität vorhanden ist: Wenn die Varianz der Fehlerterme Ei nicht konstant ist (Heteroskedastizität), kann eine gewichtete KQ-Schätzung verwendet werden, um diese Unterschiede in den Varianzen zu berücksichtigen und Verzerrungen zu vermeiden.
Unterschiedliche Präzision der Beobachtungen: Wenn verschiedene Beobachtungen unterschiedliche Präzisionen oder Zuverlässigkeiten haben, z.B. wenn einige Datenpunkte genauer sind als andere, können Gewichtungen verwendet werden, um den präziseren Beobachtungen mehr Gewicht zu geben, was zu genaueren Schätzungen führt.
In diesen Fällen verbessert die gewichtete KQ-Schätzung die Schätzung, indem sie Unterschiede in Varianz oder Präzision der Beobachtungen berücksichtigt.
(f) Erläutern Sie, anhand einer der oben aufgeführten Modelle, oder einer generellen Form des Multiplen Normalen Linearen Modells, wie eine Transformation des Modells in einer gewichteten KQ-Schätzung aussehen würde.
Transformation: Um Gewichtungen zu berücksichtigen:
Gewichtete abhängige Variable:yi∗=wiyi
Gewichtete unabhängige Variablen:xij∗=wixij
Gewichteter Fehlerterm:Ei∗=wiEi
Warum: Diese Transformation wird verwendet, um die Effekte unterschiedlicher Fehlerterme durch Gewichtungen zu berücksichtigen und Heteroskedastizität zu korrigieren.
Aufgabe 3
Aufgabenstellung
Der Datensatz college enthält Informationen zu College-Noten von 200 SchülerInnen, bei denen zu 6 Zeitpunkten (occasionit; occasionit=t, wobei t∈{0,1,2,3,4,5}) der Notendurchschnitt (gpa; gpait∈{1.7,1.8,1.9,…,3.9,4.0}) sowie wöchentliche Arbeitszeiten in einem Nebenjob (job; jobit∈{nojob,1hour,2hours,3hours,4ormorehours}) erhoben wurden. Der Datensatz enthält zudem das Geschlecht des Schülers bzw. der Schülerin (sex; sexi∈{male,female}) sowie die ID-Variable student (studenti=i).
Die Verteilung der Variable job ist wie folgt:
no job
1 hour
2 hours
3 hours
4 or more hours
0
52
967
181
0
Im Folgenden interessieren wir uns dafür, den gpa in Abhängigkeit von occasion, job und sex zu modellieren.
(a) Worauf beziehen sich die Laufindizes i und t?
Eugens Lösungen
t bezieht sich auf Messzeitpunkt
i auf den Schüler
i: Der Index i steht für die individuelle SchülerID (Student), also die spezifische Person im Datensatz. Jeder Schüler oder jede Schülerin hat eine eigene ID.
t: Der Index t steht für den Zeitpunkt oder die Messwoche, an dem die Daten erhoben wurden. Es sind insgesamt 6 Zeitpunkte (t∈{0,1,2,3,4,5}), zu denen jeweils Notendurchschnitt und Arbeitszeiten gemessen wurden.
(b) Welche Variablen sind zeitabhängig? Welche sind zeitkonstant? Begründen Sie kurz.
Eugens Lösungen
job, gpa, occasion sind zeitabhängig, de sie sich über die Zeit ändern können.
student, sex ist konstant über die Zeit.
Zeitabhängige Variablen:
gpait: Der Notendurchschnitt (gpa) ändert sich über die Zeit, da er zu verschiedenen Zeitpunkten (t) gemessen wird.
jobit: Die wöchentliche Arbeitszeit (job) kann sich ebenfalls über die Zeit ändern, da der Jobstatus und die Stundenanzahl in verschiedenen Wochen variieren können.
Zeitkonstante Variablen:
sexi: Das Geschlecht (sex) der SchülerInnen bleibt konstant über die Zeit. Es ändert sich nicht und ist daher zeitkonstant.
studenti: Die ID (student) ist ebenfalls konstant, da sie jede Person eindeutig identifiziert und sich nicht ändert.
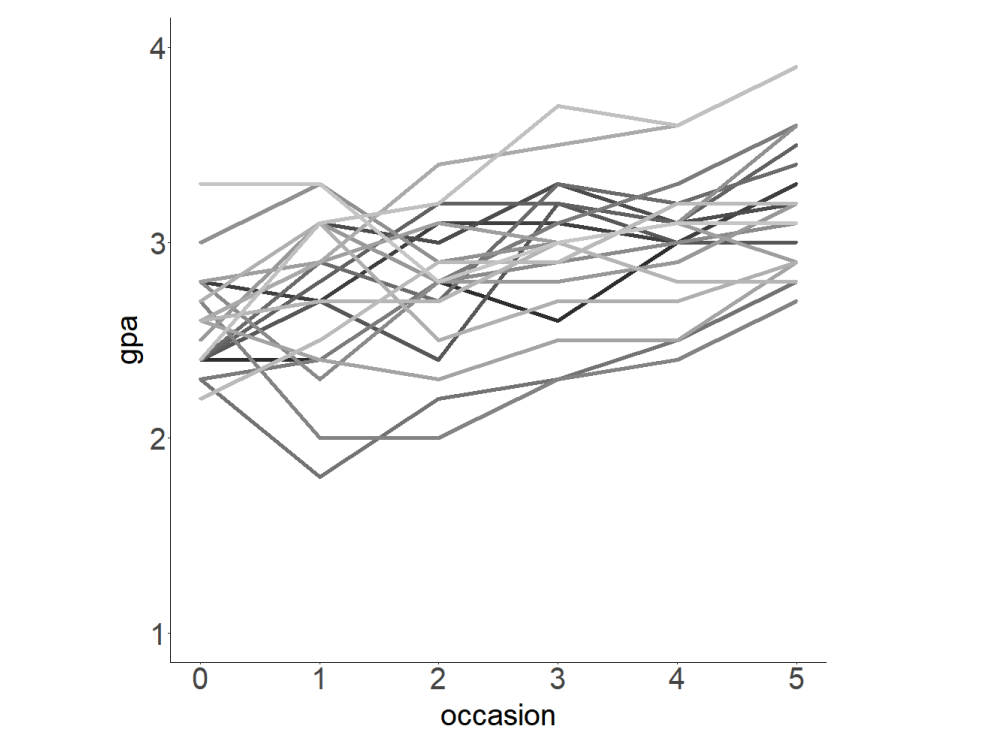
(c) Sie sehen eine Visualisierung des gpa einer Auswahl von SchülerInnen in Abhängigkeit des Zeitpunkts. Jede Verlaufskurve dieses Spaghetti-Plots entspricht dem gpa einer Person und ist in einem eigenen Grauton dargestellt. Kommentieren Sie die Visualisierung hinsichtlich des zeitlichen Verlaufs sowie der Streuung zwischen SchülerInnen.
Eugens Lösung
Es scheint einen generellen Trend nach oben zu geben. Der Verlauf eines einzelnen Schülers folgt diesem Trend, weicht aber im Durchschnitt davon ab. Die Streuung innerhalb eines Schülers ist deutlich geringer als die Streuung über alle Schüler hinweg.
Zeitlicher Verlauf:
Die meisten GPA-Werte liegen zwischen 1.8 und 3.9.
Allgemeiner leichter Anstieg der GPA-Werte über die Zeitpunkte hinweg.
Streuung zwischen SchülerInnen:
Sichtbare Streuung der GPA-Werte, zeigt Unterschiede in den Leistungen.
Überlappende Linien deuten auf ähnliche GPA-Verläufe hin.
Fazit:
Es gibt individuelle Unterschiede im GPA-Verlauf.
Insgesamt zeigt sich ein positiver Trend in den Noten.
(d) Nehmen Sie an, Sie würden für die in der Angabe genannte Fragestellung ein lineares Regressionsmodell benutzen und damit die longitudinale Struktur des Datensatzes (also die Tatsache, dass für alle SchülerInnen Wiederholungsmessungen vorliegen) ignorieren. Das entspräche folgender R-Formel: lm(gpa∼occasion+sex+job,data=college). Wie viele Beobachtungen (n) hätten Sie zur Verfügung und wie viele Parameter würden geschätzt werden? Berechnen bzw. begründen Sie jeweils kurz.
(Hinweis: Nehmen Sie an, dass die Variable occasion als stetig in das Modell aufgenommen wurde.)
Eugens Lösung
Anzahl der Beobachtungen (n)
Der Datensatz enthält 200 SchülerInnen, und für jede SchülerIn wurden die Daten zu 6 Zeitpunkten erhoben. Da jede Zeitmessung eine eigene Beobachtung ist, ergibt sich die Gesamtanzahl der Beobachtungen aus:
n=200 Schu¨lerInnen×6 Zeitpunkte=1200
Anzahl der geschätzten Parameter
Für das Modell lm(gpa∼occasion+sex+job,data=college) sind die folgenden Parameter zu schätzen:
Intercept (Achsenabschnitt): 1 Parameter
Parameter für occasion (stetig): 1 Parameter
Parameter für sex (kategorisch, 2 Kategorien: male, female): 1 Parameter (Referenzkategorie ist implizit enthalten)
Parameter für job (kategorisch, 5 Kategorien: no job, 1 hour, 2 hours, 3 hours, 4 or more hours): 4 Parameter (da eine Kategorie als Referenzkategorie weggelassen wird)
Zusammengefasst:
Intercept: 1
occasion: 1
sex: 1
job: 4
Die Gesamtanzahl der geschätzten Parameter ist daher:
1+1+1+4=7
Zusammenfassung
Anzahl der Beobachtungen (n): 1200
Anzahl der geschätzten Parameter: 7
(e) Welche Annahme des linearen Regressionsmodells wird durch die longitudinale Struktur des Datensatzes verletzt? Begründen Sie kurz.
Eugens Lösung
Unkorreliertheit des Residuenist verletzt, da die gpa Werte eines Schülers zum Zeitpunkt t2 vermutlich vom Wert zum Zeitpunkt t1 abhängen.
Die Annahme der Unabhängigkeit der Fehlerterme wird durch die longitudinale Struktur des Datensatzes verletzt.
Begründung: Bei longitudinalen Daten sind Fehlerterme innerhalb eines Individuums oft korreliert, da dieselben SchülerInnen über mehrere Zeitpunkte hinweg beobachtet werden (Autokorrelation). Diese Korrelation verletzt die Annahme, dass Fehlerterme unabhängig sind.
Die Daten sind abhängig von den Studis da mehrmals die gleichen Studenten befragt werden und diese abhängigkeit den p-Wert verzerren kann
(f) Nennen Sie zwei Ansätze, mit Mehrfachmessungen dieser Art umzugehen, sodass die oben genannte Annahme nicht verletzt wird.
Eugens Lösung
Random Intercept Modell
Zeitreihermodell
Gewichtetes KQ-Modell
Gemischte Modelle (Mixed Effects Models):
Beschreibung: Diese Modelle integrieren feste Effekte (z.B. Zeit, Geschlecht) und zufällige Effekte (z.B. individuelle Unterschiede zwischen SchülerInnen) und berücksichtigen die Korrelation der Fehler innerhalb eines Individuums.
Cluster-robuste Standardfehler:
Beschreibung: Diese Methode passt die Standardfehler der Schätzungen an, um die innerhalb von Individuen bestehende Korrelation der Fehlerterme zu berücksichtigen, indem die Fehlerkorrelation in Clustergruppen (z.B. SchülerInnen) modelliert wird.
(g) Es soll nun ein lineares gemischtes Modell mit zufälligem Intercept geschätzt werden. Welche Variable des Datensatzes sollte hier für den zufälligen Effekt gewählt werden? Begründen Sie kurz.
Für das lineare gemischte Modell mit zufälligem Intercept sollte die Schüler-ID (studenti) als Variable für den zufälligen Effekt gewählt werden.
Begründung
Individuelle Unterschiede: Der zufällige Intercept erlaubt es, individuelle Unterschiede in den Ausgangsniveaus des gpa (Notendurchschnitt) zwischen den SchülerInnen zu berücksichtigen. Jeder Schüler oder jede Schülerin kann eine unterschiedliche Ausgangsbewertung haben, die sich über die Zeit hinweg ändern kann.
Korrelation innerhalb von Individuen: Da dieselben SchülerInnen über mehrere Zeitpunkte hinweg gemessen werden, können ihre gpa-Werte korreliert sein. Ein zufälliger Intercept hilft, diese Korrelation zu modellieren, indem er individuelle Abweichungen vom durchschnittlichen Notendurchschnitt erfasst.
Durch die Wahl der Schüler-ID für den zufälligen Intercept wird sichergestellt, dass die individuelle Variation in den Noten korrekt berücksichtigt wird.
(Warum andere nicht geeignet sind:)
1. occasion (Zeitpunkt)
Warum nicht geeignet:occasion ist eine Zeitvariable und kein Individuum. Es beschreibt lediglich den Zeitpunkt der Messung und nicht die Unterschiede zwischen den SchülerInnen. Ein zufälliger Effekt für occasion würde nicht die individuelle Variation zwischen SchülerInnen berücksichtigen.
2. sex (Geschlecht)
Warum nicht geeignet:sex ist eine kategoriale Variable mit zwei Werten (male, female). Diese Variable beschreibt eine feste Eigenschaft der SchülerInnen und keine individuelle Variation innerhalb der SchülerInnen. Ein zufälliger Effekt für sex würde keine zeitlichen Veränderungen oder individuelle Unterschiede innerhalb der SchülerInnen erfassen.
3. job (Arbeitszeit)
Warum nicht geeignet:job ist eine kategoriale Variable, die die wöchentliche Arbeitszeit angibt. Diese Variable kann sich über die Zeit hinweg ändern, ist aber keine Variable, die individuelle Unterschiede in den Ausgangsniveaus des gpa abbildet. Ein zufälliger Effekt für job würde keine individuellen Unterschiede in der Basisleistung (Noten) der SchülerInnen erfassen.
4. student (Schüler-ID)
Warum geeignet:student ist die individuelle Identifikationsvariable. Ein zufälliger Intercept für student erlaubt es, die individuellen Unterschiede in den Ausgangsniveaus des gpa zu modellieren, indem er die Variation zwischen den SchülerInnen berücksichtigt und somit die Korrelation der Noten innerhalb jedes Schülers über verschiedene Zeitpunkte hinweg erfasst.
Zusammenfassung: Der zufällige Intercept sollte die Schüler-ID (student) verwenden, da sie die individuellen Unterschiede zwischen den SchülerInnen korrekt erfassen kann, während die anderen Variablen diese individuelle Variation nicht berücksichtigen.
(h) Sei xit der Vektor aller Kovariablen (inklusive Intercept) für Person i zum Zeitpunkt t, und β der Koeffizientenvektor. Stellen Sie nun die Modellgleichung des linearen gemischten Modells auf und nennen Sie die Annahmen des Modells.
Eugens Lösung
Modellgleichung des linearen gemischten Modells
gpait=xit⊤β+ui0+Eit
gpait: Notendurchschnitt für Person i zum Zeitpunkt t.
xit: Vektor der Kovariablen (einschließlich Intercept) für Person i zum Zeitpunkt t.
β: Koeffizientenvektor der festen Effekte.
ui0: Zufälliger Intercept für Person i.
Eit: Fehlerterm für Person i zum Zeitpunkt t.
Annahmen des Modells
Fehlerterme:
Eit∼Normal(0,σ2)
Fehlerterme sind unabhängig.
Zufällige Effekte:
ui0∼Normal(0,σu02)
Zufällige Effekte sind unabhängig von Fehlertermen.
Lineare Beziehung:gpait ist linear in xit.
Homoskedastizität: Varianz der Fehlerterme ist konstant.
(i) Das eben definierte gemischte lineare Modell wurde nun geschätzt. Berechnen und interpretieren Sie den Interclass Correlation Coefficient (ICC).
Modell 3i
Linear mixed model fit by REML ['lmerMod']Formula: gpa ~ occasion + job + sex + (1 | student) Data: collegeREML criterion at convergence: 322.6Scaled residuals: Min 1Q Median 3Q Max-2.99557 -0.59183 -0.01264 0.64724 2.95356Random effects: Groups Name Variance Std.Dev. student (Intercept) 0.04797 0.2190 Residual 0.05530 0.2352Number of obs: 1200, groups: student, 200Fixed effects: Estimate Std. Error t value(Intercept) 2.743392 0.047208 58.113occasion 0.102207 0.004075 25.035job2 hours -0.190378 0.038775 -4.910job3 hours -0.356756 0.043123 -8.273sexfemale 0.140503 0.033885 4.146Correlation of Fixed Effects: (Intr) occsn jb2hrs jb3hrsoccasion -0.387job2 hours -0.824 0.220job3 hours -0.758 0.190 0.872sexfemale -0.367 -0.003 -0.015 0.005
1. Bestimmung der Variance Components
Aus den Ergebnissen des gemischten Modells:
Varianz der zufälligen Effekte (student): 0.04797
Varianz der Residuen: 0.05530
2. Berechnung des ICC
Der Interclass Correlation Coefficient (ICC) wird berechnet als der Anteil der Varianz der zufälligen Effekte an der Gesamtvarianz:
ICC=Varianz der zufa¨lligen Effekte+Varianz der ResiduenVarianz der zufa¨lligen Effekte
Setzen wir die gegebenen Werte ein:
ICC=0.04797+0.055300.04797=0.103270.04797≈0.464
3. Interpretation des ICC
Der ICC von 0.464 bedeutet, dass etwa 46.4% der Gesamtvarianz in den Notendurchschnitten durch Unterschiede zwischen den SchülerInnen erklärt werden. In anderen Worten, fast die Hälfte der Variabilität in den Noten kann auf Unterschiede zwischen den SchülerInnen zurückgeführt werden, während der Rest durch Variabilität innerhalb der SchülerInnen (Fehlerterm) erklärt wird.
Dies weist darauf hin, dass es eine erhebliche individuelle Variation im Notendurchschnitt gibt, die durch den zufälligen Intercept im Modell berücksichtigt wird.
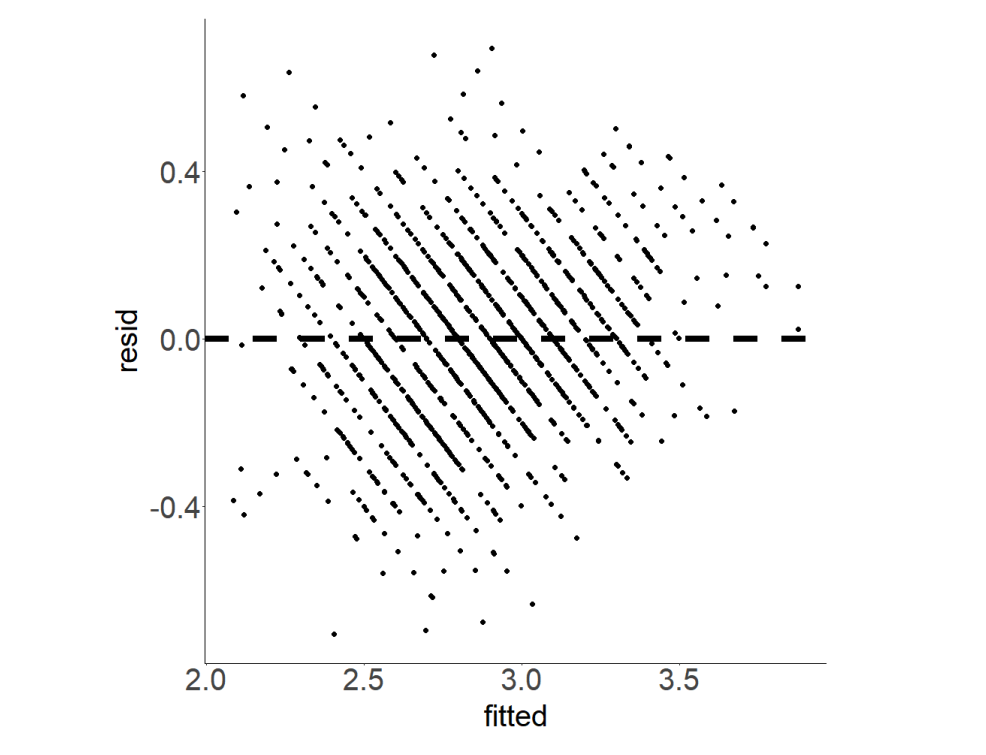
(j) Betrachten Sie nun folgendes Streudiagramm von Fitted Values (x-Achse) vs. Residuals (y-Achse), das anhand des linearen gemischten Modells, Modell 3i, erzeugt wurde. Wie erklären Sie sich, dass alle Residuen auf Diagonalen liegen, die jeweils um den Wert 0.1 verschoben sind? Was können Sie anhand des Plots zur Annahme der Homoskedastizität sagen?
Eugens Lösung
erklärt homoskedastizität besser
Erklärung der diagonalen Anordnung der Residuen
Diagonale Anordnung: Residuen liegen auf Diagonalen, jeweils um 0.1 verschoben.
Mögliche Ursache: Diskrete oder kategorische Struktur in den Prädiktorvariablen, z.B. abgerundete Messwerte oder kategoriale Variablen.
Homoskedastizität
Gleichmäßige Streuung: Residuen zeigen eine gleichmäßige Streuung über die Fitted Values hinweg.
Konstante Varianz: Keine erkennbaren Muster oder Trends in der Streuung der Residuen.
Schlussfolgerung: Die Varianz der Residuen bleibt konstant über die Fitted Values, was die Annahme der Homoskedastizität bestätigt.
Aufgabe 4
Aufgabenstellung
Bei einer Studie zu COVID-19 wird das Überleben der Infizierten nach 60 Tagen betrachtet. Es soll die Assoziation des Überlebens zum Alter (Alt; 3 Altersgruppen: 60-64, 75-79 und 90+) und zum Impfstatus (impfst; geboostert und ungeimpft) analysiert werden.
Als Zielgröße wird die Variable vst benutzt (vst=1 entspricht verstorben, vst=0 entspricht überlebt). Dazu wurden insgesamt 2 Modelle angepasst.
(a) Interpretieren Sie für folgendes Modell (Modell 4a) die geschätzten Koeffizienten von dem Impfstatus. Benutzen Sie hierzu die Odds Ratios.
Modell 4a
Call:glm(formula = vst ~ Alt + impfst, family = binomial, data = datac)Deviance Residuals: Min 1Q Median 3Q Max-0.6359 -0.0707 -0.0306 -0.0306 3.9156Coefficients: Estimate Std. Error z.B.value Pr(>|z|)(Intercept) -7.6653 0.1863 -41.15 < 2e-16 ***Alt75-79 2.7650 0.2009 13.76 < 2e-16 ***Alt90+ 4.4949 0.1875 23.97 < 2e-16 ***impfstungeimpft 1.6746 0.1087 15.40 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1(Dispersion parameter for binomial family taken to be 1) Null deviance: 4375.7 on 47344 degrees of freedomResidual deviance: 3107.0 on 47341 degrees of freedomAIC: 3115Number of Fisher Scoring iterations: 9
Der geschätzte Koeffizient für den Impfstatus (ungeimpft im Vergleich zu geboostert) beträgt 1.6746. Um dies in Odds Ratios zu interpretieren, berechnen wir:
OR=e1.6746≈5.34
Dies bedeutet, dass die Wahrscheinlichkeit zu sterben für ungeimpfte Personen etwa 5.34-mal höher ist als für geboosterte Personen, wenn alle anderen Variablen konstant gehalten werden.
(b) Berechnen Sie für den Koeffizienten von Alt75-79 das Konfidenzintervall zum Niveau α=0.05, sowohl für die log-Odds als auch für die Odds.
Schritt-für-Schritt Anleitung:
Formel für das Konfidenzintervall der log-Odds:
Das 95%-Konfidenzintervall für den Koeffizienten wird berechnet als:
CIlog−odds=β^±zα/2⋅SE
Bestimmen Sie den Koeffizienten ((\hat{\beta})) und den Standardfehler (SE):
Koeffizient für Alt75-79: β^=2.7650
Standardfehler für Alt75-79: SE=0.2009
Bestimmen Sie den z-Wert für das Konfidenzniveau:
Für α=0.05 und z0.025≈1.96.
Berechnen Sie das Konfidenzintervall für die log-Odds:
Konvertieren Sie das Konfidenzintervall der log-Odds in das Konfidenzintervall der Odds:
CIodds=eCIlog−odds
Berechnen Sie die Exponentialfunktion für beide Grenzen des Intervalls:
CIodds=[e2.3712,e3.1588]
Berechnen Sie die exakten Werte:
CIodds≈[10.71,23.54]
Zusammenfassung:
Das 95%-Konfidenzintervall für den Koeffizienten von Alt75-79 (log-Odds) ist [2.3712,3.1588].
Das 95%-Konfidenzintervall für die Odds ist [10.71,23.54].
(c) Für den Koeffizienten des Impfstatus (impfstungeimpft) ist der Wert 0 nicht im 95%-Konfidenzintervall enthalten. Was bedeutet das für einen ungerichteten Hypothesentest des Odds Ratios des Impfstatus mit Nullhypothese H0: Odds Ratio = 1 und Gegenhypothese H1: Odds Ratio ungleich 1 zum Niveau α=0.05? Begründen Sie kurz.
Da 0 nicht im 95%-Konfidenzintervall des Koeffizienten enthalten ist, wird die Nullhypothese H0 verworfen. Dies bedeutet, dass es einen signifikanten Unterschied im Überleben zwischen den ungeimpften und geboosterten Personen gibt. Der Odds Ratio ungleich 1 weist darauf hin, dass der Impfstatus einen signifikanten Einfluss auf die Wahrscheinlichkeit des Überlebens hat.
(d) Geben Sie für Modell 4a die Struktur- und Verteilungsannahme an. Spezifizieren Sie explizit den linearen Prädiktor sowie die Response- und Link-Funktion.
Strukturannahme:
Binomialverteilung für die Zielvariable vst (verstorben/überlebt)
(e) Nun wird ein weiteres Modell (Modell 4e) geschätzt:
Call:glm(formula = vst ~ Alt + impfst + Alt * impfst, family = binomial, data = datac)Deviance Residuals: Min 1Q Median 3Q Max-0.5849 -0.0774 -0.0255 -0.0255 4.0074Coefficients: Estimate Std. Error z.B.value Pr(>|z|)(Intercept) -8.0293 0.3333 -24.089 < 2e-16 ***Alt75-79 2.7653 0.3718 7.437 1.03e-13 ***Alt90+ 5.0575 0.3466 14.590 < 2e-16 ***impfstungeimpft 2.2189 0.3910 5.675 1.39e-08 ***Alt75-79:impfstungeimpft 0.1069 0.4425 0.242 0.8091Alt90+:impfstungeimpft -0.9262 0.4143 -2.235 0.0254 *---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1(Dispersion parameter for binomial family taken to be 1) Null deviance: 4375.7 on 47344 degrees of freedomResidual deviance: 3086.9 on 47339 degrees of freedomAIC: 3098.9Number of Fisher Scoring iterations: 10
(f) Welche zusätzliche Fragestellung wird in Modell 4e, im Vergleich zu Modell 4a, bearbeitet? Erklären Sie.
Eugens Lösung
Es wird berücksichtigt, ob des Effekt von der Impfung mit dem Alter zusammenhängt. So scheint eine Impfung im Alter 90+ mehr zu bringen als bei 60-64.
In Modell 4e wird untersucht, ob es eine Wechselwirkung zwischen Alter und Impfstatus gibt, also ob der Effekt des Impfstatus auf das Überleben je nach Altersgruppe unterschiedlich ist. Dies wird durch die Interaktionsterme Alt∗impfst berücksichtigt.
(g) Vergleichen Sie die Ergebnisse von Modell 4a und Modell 4e inhaltlich im Hinblick auf Alters- und Impfstatus-Effekte. Welches Modell ist zu bevorzugen? Begründen Sie.
Eugens Lösung
Modell 4e zeigt, dass es signifikante Interaktionen zwischen Alter und Impfstatus gibt (z.B. Alt90+:impfstungeimpft ist signifikant mit p=0.0254). Dies deutet darauf hin, dass der Effekt des Impfstatus auf das Überleben von der Altersgruppe abhängt. Das Modell 4e ist daher vorzuziehen, da es diese komplexere Beziehung berücksichtigt und eine genauere Modellierung der Daten ermöglicht.
(i) Welches Modell ist zu bevorzugen? Begründen Sie kurz.
Modell 4e ist zu bevorzugen, da die ANOVA zeigt, dass die Interaktion zwischen Alter und Impfstatus signifikant ist (p<0.001). Dies bedeutet, dass Modell 4e eine bessere Passform bietet, da es die signifikante Wechselwirkung zwischen Alter und Impfstatus berücksichtigt.
×
MyUniNotes is a free, non-profit project to make education accessible for everyone.
If it has helped you, consider giving back! Even a small donation makes a difference.
These are my personal notes. While I strive for accuracy, I’m still a student myself. Thanks for being part of this journey!




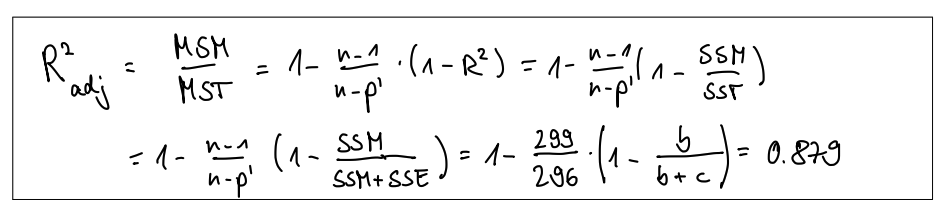



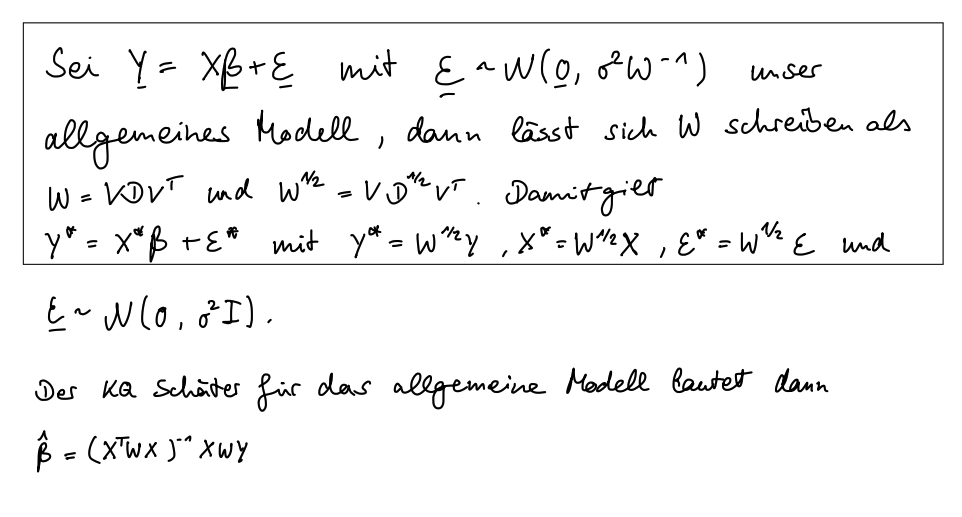


erklärt homoskedastizität besser
