Aufgabe 10.1: Grid und Cloud
Erklären Sie die wesentlichen Unterschiede zwischen Grids und Clouds.
| Grid Computing | Cloud Computing |
|---|---|
| Zugriff auf gemeinsame Rechenleistung, Speicher und andere Ressourcen | Zugriff auf gemietete Rechenleistung, Speicher und andere Ressourcen |
| Große Organisationen bezahlen für die Dienste (Universitäten/Regierung) | Nutzer zahlen für die gemieteten Dienste |
| Wird von Anbietern und Nutzern (Universitäten/Regierung) verwaltet | Wird ausschließlich von Cloud-Anbietern verwaltet. Keine Rolle für den Nutzer. |
| Große Organisationen stellen die Dienste bereit (Universitäten/Regierung/Forschungseinrichtungen) | Kommerzielle Unternehmen stellen die Dienste bereit |
| Verarbeitet große Datenmengen, komplexe Berechnungen (z. B. Wettervorhersagen) | Verarbeitet (in der Regel) eine angemessene Menge an Daten für kommerzielle und andere Organisationen |
| Geeignet für Forschungseinrichtungen zur Durchführung von Aufgaben wie globaler Klimamodellierung usw. | Geeignet für Unternehmen, um effektiv Computing zu nutzen, ohne zu investieren |
- Cloud Computing
- Bereitstellung von IT-Ressourcen (z. B. Rechenleistung, Speicherplatz, Anwendungen) über das Internet
- On-Demand-Zugriff mit nutzungsabhängiger Abrechnung
- Skalierbarkeit und Elastizität durch zentrale Anbieter
- Grid Computing
- Zusammenschaltung verteilter Computerressourcen zu einem virtuellen Supercomputer
- Gemeinsame Nutzung von Rechenleistung zur Lösung komplexer, rechenintensiver Probleme
- Meist in wissenschaftlichen oder technischen Anwendungen eingesetzt
Aufgabe 10.2: Fragen zur Vorlesung und Übung
Arbeiten Sie das gesamte Skript durch. Sollten dabei Fragen aufkommen, antworten Sie bitte bis spätestens Mittwoch, 5. Februar 2025 im Diskussionsforum in Moodle Moodle-Link.
Diese werden dann am Freitag in der Vorlesung besprochen.
Besipielfragen
Allgemeine Fragen zu Grid und Cloud
- Wie unterscheiden sich die grundlegenden Architekturen von Grid und Cloud Computing?
- Welche Arten von Anwendungen eignen sich besser für Grid Computing, und welche für Cloud Computing?
- Wie beeinflusst die Virtualisierung die Entwicklung von Grid und Cloud Computing?
- Welche Rolle spielen Sicherheitsaspekte in Grid- und Cloud-Umgebungen, und wie werden diese adressiert?
- Wie hat sich die Technologie in den letzten Jahren entwickelt, und welche Trends sind für die Zukunft zu erwarten?
Fragen zu Grid Computing
- Welche Vorteile bietet die Nutzung von Grid Computing für wissenschaftliche und technische Anwendungen?
- Wie werden Ressourcen in einem Grid-System verwaltet und zugeteilt?
- Welche Herausforderungen gibt es bei der Entwicklung und dem Betrieb von Grid-Infrastrukturen?
- Können Sie Beispiele für erfolgreiche Grid-Computing-Projekte nennen?
- Wie hat sich Grid Computing im Vergleich zu traditionellen Hochleistungsrechnen entwickelt?
Fragen zu Cloud Computing
- Welche verschiedenen Cloud-Service-Modelle (IaaS, PaaS, SaaS) gibt es, und wie unterscheiden sie sich?
- Wie ermöglicht Cloud Computing die Skalierung von Anwendungen und Ressourcen?
- Welche Vorteile bietet die Nutzung von Cloud Computing für Unternehmen und Organisationen?
- Welche Risiken sind mit der Nutzung von Cloud-Diensten verbunden, und wie können diese minimiert werden?
- Wie hat sich Cloud Computing in den letzten Jahren entwickelt, und welche neuen Trends gibt es?
Vergleichende Fragen
- Welche Gemeinsamkeiten und Unterschiede gibt es zwischen Grid und Cloud Computing in Bezug auf Skalierbarkeit, Flexibilität und Kosten?
- In welchen Bereichen ergänzen sich Grid und Cloud Computing, und wo gibt es Überschneidungen?
- Wie können Unternehmen von der Kombination von Grid- und Cloud-Technologien profitieren?
- Welche Faktoren sollten bei der Entscheidung zwischen Grid und Cloud Computing berücksichtigt werden?
- Wie werden sich Grid und Cloud Computing in Zukunft weiterentwickeln und möglicherweise konvergieren?
Beispiellösung zu den Fragen
Allgemeine Fragen zu Grid und Cloud
1. Wie unterscheiden sich die grundlegenden Architekturen von Grid und Cloud Computing?
Grid Computing:
- Dezentrale und heterogene Ressourcen: Grid Computing verbindet häufig geografisch verteilte, heterogene Systeme (Server, Arbeitsstationen, Cluster), die oft von verschiedenen Organisationen oder Personen bereitgestellt werden.
- Föderation mehrerer administrativer Domänen: Ressourcen werden über unterschiedliche Verwaltungsbereiche hinweg geteilt, was zu einer dezentralen Steuerung führt.
- Spezialisierte Middleware: Um die Vielfalt der Hardware und Betriebssysteme zu vereinen, kommen spezielle Software-Middleware-Lösungen (z. B. Globus Toolkit) zum Einsatz, die Aufgaben wie Authentifizierung, Autorisierung, Job-Scheduling und Ressourcenverwaltung übernehmen.
- Ziel: Vor allem die Lösung rechenintensiver, oft batchorientierter wissenschaftlicher und technischer Aufgaben.
Cloud Computing:
- Zentralisierte Ressourcenkonzepte: Cloud-Architekturen basieren auf großen, virtualisierten Rechenzentren, die zentral verwaltet werden.
- Virtualisierung: Kernstück der Cloud-Technologie ist die Virtualisierung, welche physische Ressourcen in flexible, skalierbare virtuelle Ressourcen abstrahiert.
- Service-orientierte Bereitstellung: Dienste werden als Service (z. B. IaaS, PaaS, SaaS) über das Internet angeboten.
- Automatisierung und On-Demand-Nutzung: Nutzer können Ressourcen dynamisch und automatisiert je nach Bedarf skalieren, wodurch ein hoher Grad an Flexibilität und Elastizität erreicht wird.
2. Welche Arten von Anwendungen eignen sich besser für Grid Computing, und welche für Cloud Computing?
Grid Computing:
- Rechenintensive wissenschaftliche Anwendungen: Simulationen, numerische Berechnungen, Wettermodelle, Klimasimulationen und physikalische Berechnungen (z. B. Teilchenphysik) profitieren von der Möglichkeit, große Mengen an Rechenleistung aus verteilten Systemen zu nutzen.
- Batch-Prozesse und Analysen: Aufgaben, die über längere Zeiträume in nicht interaktiven, batchorientierten Jobs abgearbeitet werden können, lassen sich gut in einem Grid realisieren.
- Projekte mit hoher Parallelisierbarkeit: Anwendungen, die in viele unabhängige Teilaufgaben zerlegt werden können (z. B. verteilte Datenanalysen), sind prädestiniert für Grid-Umgebungen.
Cloud Computing:
- Webanwendungen und mobile Apps: Anwendungen, die eine hohe Verfügbarkeit und schnelle Skalierbarkeit benötigen, profitieren von der elastischen Infrastruktur der Cloud.
- Dynamische und variable Workloads: Unternehmen, die schwankende Lasten haben (z. B. saisonale E-Commerce-Anwendungen), können in der Cloud bedarfsgerecht Ressourcen anfordern und wieder freigeben.
- Software-as-a-Service (SaaS): Anwendungen, die als Dienste bereitgestellt werden (z. B. CRM-Systeme, Office-Suites), lassen sich aufgrund des zentralisierten Managements und der Benutzerfreundlichkeit optimal in der Cloud betreiben.
- Entwicklungs- und Testumgebungen: PaaS-Angebote erleichtern Entwicklern das schnelle Aufsetzen von Test- und Entwicklungsumgebungen ohne hohen administrativen Aufwand.
3. Wie beeinflusst die Virtualisierung die Entwicklung von Grid und Cloud Computing?
Einfluss auf Cloud Computing:
- Ressourcenabstraktion: Virtualisierung trennt Hardware von Software, sodass physische Ressourcen in virtuelle Einheiten umgewandelt werden können. Dies ermöglicht die flexible Zuteilung von CPU, Speicher, und Netzwerkressourcen.
- Skalierbarkeit und Elastizität: Durch virtuelle Maschinen (VMs) und Container können Ressourcen dynamisch erweitert oder reduziert werden – ein Kernelement des Cloud-Computing-Modells.
- Isolation und Sicherheit: Virtualisierung bietet eine gewisse Isolierung zwischen den einzelnen Instanzen, was vor Störungen und Sicherheitsproblemen schützt.
Einfluss auf Grid Computing:
- Verbesserte Ressourcenverwaltung: Auch in Grid-Umgebungen wird zunehmend Virtualisierung eingesetzt, um heterogene Ressourcen zu vereinheitlichen und effizienter zu nutzen.
- Flexibilisierung bestehender Infrastrukturen: Durch Virtualisierung können vorhandene physische Ressourcen in mehreren Grid-Projekten gleichzeitig genutzt werden, ohne dass direkte Wechselwirkungen auftreten.
- Herausforderungen: Während Cloud Computing auf Virtualisierung als zentrales Paradigma setzt, ist Grid Computing historisch oft auf physische, nicht virtualisierte Systeme angewiesen. Moderne Grid-Systeme integrieren jedoch vermehrt Virtualisierung, um von deren Vorteilen zu profitieren.
4. Welche Rolle spielen Sicherheitsaspekte in Grid- und Cloud-Umgebungen, und wie werden diese adressiert?
Sicherheitsaspekte in Grid Computing:
- Authentifizierung und Autorisierung: Aufgrund der Beteiligung mehrerer Organisationen kommen häufig X-Zertifikate, Kerberos oder andere Public-Key-Infrastrukturen zum Einsatz, um sicherzustellen, dass nur autorisierte Nutzer und Prozesse auf die Ressourcen zugreifen können.
- Vertrauensmanagement: In einem dezentralen Umfeld ist das Etablieren von Vertrauensbeziehungen zwischen den beteiligten Domänen essenziell.
- Datenintegrität und -verschlüsselung: Die Übertragung und Speicherung von Daten erfolgt häufig verschlüsselt, um Manipulationen zu verhindern.
Sicherheitsaspekte in Cloud Computing:
- Multi-Tenancy und Isolation: Da Ressourcen von mehreren Kunden geteilt werden, ist die Isolation zwischen den Mandanten von hoher Bedeutung. Virtualisierungstechniken und Container-Isolierung spielen hierbei eine zentrale Rolle.
- Compliance und Datenschutz: Cloud-Anbieter müssen sicherstellen, dass Daten gemäß gesetzlichen und regulatorischen Vorgaben verarbeitet und gespeichert werden.
- Sicherheitsprotokolle und Zugriffsmanagement: Moderne Authentifizierungsmechanismen (z. B. OAuth, Multi-Faktor-Authentifizierung) und kontinuierliche Sicherheitsüberwachung sind Standard, um potenzielle Bedrohungen frühzeitig zu erkennen und abzuwehren.
5. Wie hat sich die Technologie in den letzten Jahren entwickelt, und welche Trends sind für die Zukunft zu erwarten?
Entwicklung der letzten Jahre:
- Verlagerung von Grid zu Cloud: Während Grid Computing in den frühen 2000er-Jahren vor allem für wissenschaftliche Anwendungen eine große Rolle spielte, hat Cloud Computing aufgrund seiner Flexibilität und Skalierbarkeit in vielen Bereichen an Bedeutung gewonnen.
- Verstärkter Einsatz von Virtualisierung: Sowohl in Grid- als auch in Cloud-Umgebungen hat die Virtualisierung an Bedeutung gewonnen, wobei Container-Technologien (z. B. Docker, Kubernetes) zunehmend eingesetzt werden.
- Hybrid- und Multi-Cloud-Strategien: Unternehmen kombinieren zunehmend private Rechenzentren mit öffentlichen Cloud-Diensten, um Flexibilität und Kontrolle zu erhöhen.
Zukünftige Trends:
- Edge Computing: Mit dem Wachstum von IoT und Echtzeitanwendungen werden verteilte, dezentralisierte Rechenmodelle an Bedeutung gewinnen, bei denen Cloud- und Edge-Ressourcen kombiniert werden.
- Serverless Computing: Die Entwicklung hin zu noch stärker abstrahierten Diensten, bei denen die Infrastruktur komplett vom Anbieter gemanagt wird, wird weiter voranschreiten.
- Künstliche Intelligenz und Automatisierung: Der Einsatz von KI zur Optimierung von Ressourcenmanagement, Sicherheitsüberwachung und Fehlerdiagnose in beiden Umgebungen wird zunehmen.
- Konvergenz von Technologien: Es ist zu erwarten, dass sich Grid- und Cloud-Technologien weiter annähern, etwa durch die Integration von Grid-ähnlichen Funktionen in Cloud-Plattformen und den verstärkten Einsatz von Virtualisierung in Grid-Umgebungen.
Fragen zu Grid Computing
6. Welche Vorteile bietet die Nutzung von Grid Computing für wissenschaftliche und technische Anwendungen?
- Hohe Rechenleistung: Durch die Bündelung zahlreicher, oft geografisch verteilter Rechner können sehr rechenintensive Aufgaben parallel bearbeitet werden.
- Ressourcenteilung: Wissenschaftliche Einrichtungen können ihre vorhandenen, teils überqualifizierten Ressourcen gemeinsam nutzen, ohne in eigene teure Supercomputer investieren zu müssen.
- Kollaboration: Grid Computing fördert die Zusammenarbeit zwischen verschiedenen Institutionen, da Ressourcen und Daten über administrative Grenzen hinweg geteilt werden können.
- Kostenersparnis: Durch die Nutzung vorhandener Ressourcen und die gemeinsame Infrastruktur sinken die Investitions- und Betriebskosten im Vergleich zu traditionellen HPC-Systemen (High Performance Computing).
7. Wie werden Ressourcen in einem Grid-System verwaltet und zugeteilt?
- Middleware-Lösungen: Spezialisierte Software (z. B. Globus Toolkit, gLite, Condor) übernimmt das Management der heterogenen Ressourcen.
- Job-Scheduling: Aufgaben werden durch Scheduler (Job-Manager) auf die verfügbaren Ressourcen verteilt. Diese Scheduler berücksichtigen dabei Faktoren wie Verfügbarkeit, Rechenleistung, Prioritäten und Netzwerklatenzen.
- Ressourcenüberwachung: Kontinuierliche Monitoring-Tools stellen sicher, dass der Zustand der einzelnen Rechner oder Knoten bekannt ist, sodass bei Ausfällen oder hoher Auslastung alternative Ressourcen zugewiesen werden können.
- Interoperabilität: Durch standardisierte Protokolle und Schnittstellen wird gewährleistet, dass verschiedene Systeme miteinander kommunizieren und Aufgaben effizient verteilt werden.
8. Welche Herausforderungen gibt es bei der Entwicklung und dem Betrieb von Grid-Infrastrukturen?
- Heterogenität der Ressourcen: Unterschiedliche Hardware, Betriebssysteme und Verwaltungsrichtlinien erfordern komplexe Middleware und Standards.
- Sicherheitsmanagement: Die Sicherstellung eines konsistenten Sicherheitsniveaus über mehrere administrative Domänen hinweg ist komplex, insbesondere bei der Authentifizierung und Autorisierung.
- Netzwerk- und Latenzprobleme: Geografisch verteilte Systeme sind anfälliger für Netzwerkverzögerungen, was die Synchronisation und Datenübertragung beeinträchtigen kann.
- Fehlertoleranz und Zuverlässigkeit: Die Integration zahlreicher unabhängiger Systeme erhöht die Wahrscheinlichkeit von Ausfällen; daher sind robuste Mechanismen zur Fehlererkennung und -behebung erforderlich.
- Komplexität des Managements: Die Koordination, Überwachung und Wartung einer großen Anzahl verteilter Knoten erfordert spezialisierte Tools und Fachwissen.
9. Können Sie Beispiele für erfolgreiche Grid-Computing-Projekte nennen?
- SETI@home: Ein bekanntes Projekt, bei dem freiwillige Rechner ihre Leerlaufzeiten nutzen, um Radiowellen-Daten auf außerirdische Signale zu untersuchen.
- Worldwide LHC Computing Grid (WLCG): Ein globales Grid, das die riesigen Datenmengen aus Experimenten am Large Hadron Collider (LHC) verarbeitet und analysiert.
- EGEE (Enabling Grids for E-sciencE): Ein europäisches Grid-Projekt, das wissenschaftliche Forschung über verteilte Rechenressourcen unterstützt hat.
- TeraGrid/XSEDE: Initiativen in den USA, die Zugang zu Hochleistungsrechenressourcen für wissenschaftliche Anwendungen ermöglichten.
10. Wie hat sich Grid Computing im Vergleich zu traditionellen Hochleistungsrechnen entwickelt?
- Verteilte vs. zentrale Systeme: Während traditionelles Hochleistungsrechnen (HPC) oft auf zentralisierten Supercomputern oder Clustern basiert, nutzt Grid Computing verteilte Ressourcen, die oft über verschiedene Standorte und Organisationen verteilt sind.
- Flexibilität und Zugänglichkeit: Grid Computing ermöglicht es, vorhandene, oft untergenutzte Ressourcen effizient zu integrieren, wodurch auch kleinere Institutionen Zugang zu Hochleistungsrechnen erhalten.
- Skalierbarkeit: Durch die Integration zahlreicher Ressourcen können Grid-Systeme theoretisch nahezu unbegrenzte Rechenleistung bereitstellen, wenngleich dies auch zu Herausforderungen bei der Koordination und Latenz führt.
- Anwendungsfelder: Während HPC häufig für stark gekoppelte numerische Simulationen eingesetzt wird, eignet sich Grid Computing besser für parallele, lose gekoppelte Aufgaben, die in unabhängige Teilprozesse zerlegt werden können.
Fragen zu Cloud Computing
11. Welche verschiedenen Cloud-Service-Modelle (IaaS, PaaS, SaaS) gibt es, und wie unterscheiden sie sich?
- IaaS (Infrastructure as a Service):
- Angebot: Grundlegende IT-Infrastruktur – virtuelle Maschinen, Speicher, Netzwerke und andere Rechenressourcen.
- Beispiel: Amazon EC2, Google Compute Engine.
- Zielgruppe: Unternehmen, die Kontrolle über Betriebssysteme und Anwendungen benötigen, ohne in eigene Hardware zu investieren.
- PaaS (Platform as a Service):
- Angebot: Eine Entwicklungs- und Laufzeitumgebung, die den gesamten Infrastruktur- und Plattform-Stack abstrahiert.
- Beispiel: Google App Engine, Microsoft Azure App Service, Heroku.
- Zielgruppe: Entwickler, die sich auf die Anwendungsentwicklung konzentrieren wollen, ohne sich um die darunterliegende Infrastruktur kümmern zu müssen.
- SaaS (Software as a Service):
- Angebot: Fertig entwickelte Softwarelösungen, die über das Internet bereitgestellt werden.
- Beispiel: Salesforce, Microsoft Office 365, Google Workspace.
- Zielgruppe: Endnutzer und Unternehmen, die sofortige, gebrauchsfertige Anwendungen benötigen.
12. Wie ermöglicht Cloud Computing die Skalierung von Anwendungen und Ressourcen?
- Elastizität: Cloud-Plattformen bieten die Möglichkeit, Ressourcen dynamisch nach Bedarf hinzuzufügen oder zu reduzieren.
- Auto-Scaling: Viele Cloud-Anbieter stellen Funktionen bereit, mit denen Anwendungen basierend auf definierten Metriken (z. B. CPU-Auslastung, Netzwerkverkehr) automatisch skaliert werden.
- Load Balancing: Durch den Einsatz von Lastverteilern wird der Datenverkehr effizient auf mehrere Instanzen verteilt, was die Performance und Verfügbarkeit erhöht.
- Container-Orchestrierung: Technologien wie Kubernetes ermöglichen eine noch feinere Steuerung und Skalierung von containerisierten Anwendungen.
13. Welche Vorteile bietet die Nutzung von Cloud Computing für Unternehmen und Organisationen?
- Kosteneffizienz: Das „Pay-as-you-go“-Modell reduziert Investitionskosten, da nur die tatsächlich genutzten Ressourcen bezahlt werden.
- Flexibilität und Agilität: Unternehmen können schnell neue Anwendungen bereitstellen und auf Marktveränderungen reagieren.
- Reduzierter administrativer Aufwand: Die Verwaltung der physischen Infrastruktur wird vom Cloud-Anbieter übernommen, sodass sich Unternehmen auf ihre Kerngeschäfte konzentrieren können.
- Globale Verfügbarkeit: Cloud-Dienste sind in der Regel weltweit über Rechenzentren verfügbar, was eine hohe Ausfallsicherheit und geographische Redundanz ermöglicht.
- Innovationsförderung: Der Zugang zu neuesten Technologien (z. B. Machine Learning, Big Data Analytics) ermöglicht es Unternehmen, innovative Lösungen zu entwickeln, ohne hohe Vorabinvestitionen zu tätigen.
14. Welche Risiken sind mit der Nutzung von Cloud-Diensten verbunden, und wie können diese minimiert werden?
Risiken:
- Datensicherheit und Datenschutz: Daten in der Cloud können anfällig für Sicherheitsverletzungen sein.
- Compliance und rechtliche Vorgaben: Unterschiedliche regionale Datenschutzgesetze und Compliance-Anforderungen müssen eingehalten werden.
- Vendor Lock-in: Die starke Abhängigkeit von einem Cloud-Anbieter kann den Wechsel zu anderen Anbietern erschweren.
- Verfügbarkeitsrisiken: Netzwerkausfälle oder Serviceunterbrechungen des Anbieters können den Geschäftsbetrieb beeinträchtigen.
Minimierung der Risiken:
- Verschlüsselung und Sicherheitsprotokolle: Daten sollten während der Übertragung und im Ruhezustand verschlüsselt werden.
- Multi-Cloud- und Hybrid-Cloud-Strategien: Durch den Einsatz mehrerer Anbieter oder die Kombination von Cloud- und On-Premise-Ressourcen kann das Risiko des Vendor Lock-in reduziert werden.
- Regelmäßige Audits und Compliance-Prüfungen: Unternehmen sollten sicherstellen, dass ihre Cloud-Dienste den gesetzlichen Anforderungen entsprechen.
- SLA-Vereinbarungen und Notfallpläne: Klare Service Level Agreements (SLAs) und Disaster-Recovery-Pläne tragen dazu bei, Unterbrechungen und Datenverluste zu minimieren.
15. Wie hat sich Cloud Computing in den letzten Jahren entwickelt, und welche neuen Trends gibt es?
Entwicklung:
- Massenadoption: Cloud Computing ist inzwischen in nahezu allen Branchen angekommen – von Start-ups bis hin zu Großunternehmen.
- Erweiterung des Service-Portfolios: Anbieter haben ihr Angebot über grundlegende Infrastruktur hinaus um spezialisierte Dienste wie KI, Big Data, IoT und serverlose Architekturen erweitert.
- Verbesserte Sicherheit und Compliance: Mit wachsender Nutzung wurden Sicherheitsstandards und Zertifizierungen weiterentwickelt.
Neue Trends:
- Serverless Computing: Anwendungen werden als Funktionen ausgeführt, ohne dass Infrastruktur verwaltet werden muss.
- Edge Computing: Rechenleistung wird näher an den Datenquellen (z. B. IoT-Geräte) bereitgestellt, um Latenzzeiten zu minimieren.
- Künstliche Intelligenz (KI) und Machine Learning (ML): Integrierte KI-Dienste ermöglichen es Unternehmen, intelligente Anwendungen ohne großen eigenen Entwicklungsaufwand zu betreiben.
- Hybrid- und Multi-Cloud-Ansätze: Unternehmen nutzen zunehmend eine Kombination aus privaten Rechenzentren und öffentlichen Cloud-Diensten, um Flexibilität und Kontrolle zu maximieren.
Vergleichende Fragen
16. Welche Gemeinsamkeiten und Unterschiede gibt es zwischen Grid und Cloud Computing in Bezug auf Skalierbarkeit, Flexibilität und Kosten?
Gemeinsamkeiten:
- Verteilte Ressourcen: Beide Modelle nutzen verteilte Ressourcen, um Rechenleistung bereitzustellen.
- Ziel der Ressourcenauslastung: Sowohl Grid als auch Cloud zielen darauf ab, vorhandene Ressourcen optimal zu nutzen.
Unterschiede:
- Skalierbarkeit:
- Cloud Computing bietet eine hohe Elastizität und ermöglicht eine automatische, On-Demand-Skalierung.
- Grid Computing skaliert durch das Hinzufügen von Ressourcen aus verschiedenen administrativen Domänen, ist aber oft weniger dynamisch und erfordert manuelle Abstimmungen.
- Flexibilität:
- Cloud Computing bietet flexible Service-Modelle (IaaS, PaaS, SaaS) und eine starke Virtualisierungsschicht, die die Anpassung an unterschiedliche Workloads erleichtert.
- Grid Computing ist häufig auf spezifische, oft wissenschaftliche Anwendungen ausgerichtet und weniger auf schnelle Anpassung an wechselnde Geschäftsanforderungen.
- Kosten:
- Cloud Computing arbeitet in der Regel mit einem Pay-as-you-go-Modell, wodurch Investitionskosten minimiert werden, aber bei falscher Ausnutzung auch Betriebskosten steigen können.
- Grid Computing basiert oft auf der Nutzung vorhandener Ressourcen und gemeinschaftlicher Kooperation, was in bestimmten Kontexten zu Kosteneinsparungen führen kann, jedoch auch hohen administrativen Aufwand bedeuten kann.
17. In welchen Bereichen ergänzen sich Grid und Cloud Computing, und wo gibt es Überschneidungen?
- Ergänzung:
- Hochleistungsrechnen (HPC): Wissenschaftliche und forschungsintensive Anwendungen können Grid Computing für massive, parallelisierte Berechnungen nutzen, während Cloud Computing als flexible Ergänzung für zusätzliche, kurzfristige Rechenlasten dient.
- Hybrid-Lösungen: Unternehmen können traditionelle Grid-Infrastrukturen mit Cloud-Ressourcen erweitern, um Lastspitzen abzufangen oder neue Dienste schneller zu implementieren.
- Überschneidungen:
- Beide Modelle setzen auf verteilte Systeme und moderne Netzwerkprotokolle, wodurch sich teilweise ähnliche Middleware- und Sicherheitslösungen finden.
- Sowohl in Grid als auch in Cloud-Umgebungen werden Virtualisierung und Containerisierung genutzt, um Ressourcen effizient zu verwalten.
18. Wie können Unternehmen von der Kombination von Grid- und Cloud-Technologien profitieren?
- Optimierte Ressourcennutzung:
- Unternehmen können ihre vorhandenen, möglicherweise spezialisierten Grid-Ressourcen weiter nutzen und durch die Flexibilität der Cloud bei Bedarf skalieren.
- Kosteneffizienz:
- Durch das Outsourcing von Lastspitzen an die Cloud können teure Investitionen in zusätzliche Hardware vermieden werden.
- Erhöhte Agilität:
- Hybride Architekturen ermöglichen eine schnelle Anpassung an wechselnde Geschäftsanforderungen, da traditionelle Grid-Lösungen mit modernen Cloud-Diensten kombiniert werden.
- Innovationsförderung:
- Die Kombination bietet die Möglichkeit, neue Technologien (z. B. KI, Big Data) in bestehende Rechenumgebungen zu integrieren, ohne komplette Infrastrukturen neu aufzubauen.
19. Welche Faktoren sollten bei der Entscheidung zwischen Grid und Cloud Computing berücksichtigt werden?
- Anwendungsanforderungen:
- Ist die Anwendung stark parallelisierbar und rechenintensiv (geeignet für Grid), oder benötigt sie schnelle, flexible Skalierung und hohe Verfügbarkeit (geeignet für Cloud)?
- Kostenstruktur:
- Welche Investitions- und Betriebskosten sind zu erwarten, und welche Zahlungsmodelle (z. B. Pay-as-you-go vs. feste Ressourcenkonzepte) passen besser zum Geschäftsmodell?
- Sicherheits- und Compliance-Anforderungen:
- Welche Datenschutzvorgaben, Zertifizierungen und Sicherheitsstandards müssen eingehalten werden?
- Technologische Infrastruktur:
- Welche vorhandenen Systeme und Technologien sind bereits im Einsatz, und wie einfach können diese integriert oder erweitert werden?
- Verwaltungsaufwand:
- Wie komplex ist das Management der Infrastruktur, und steht das nötige Fachwissen zur Verfügung?
20. Wie werden sich Grid und Cloud Computing in Zukunft weiterentwickeln und möglicherweise konvergieren?
- Integration von Virtualisierungstechnologien:
- Beide Modelle profitieren weiterhin von Fortschritten in der Virtualisierung, Containerisierung und Orchestrierung, was zu einer Annäherung der Managementkonzepte führt.
- Hybrid- und Multi-Cloud-Strategien:
- Die Zukunft wird vermehrt hybride Infrastrukturen sehen, in denen lokale Grid-Ressourcen nahtlos mit Cloud-Diensten kombiniert werden, um maximale Flexibilität und Kosteneffizienz zu erreichen.
- Edge Computing und IoT:
- Mit der Zunahme von IoT-Geräten und dezentralen Anwendungen wird sich die Rechenleistung immer weiter vom zentralen Rechenzentrum an den Netzwerkrand verlagern – ein Bereich, in dem Elemente beider Ansätze Anwendung finden.
- Automatisierung und KI:
- Durch den Einsatz von Künstlicher Intelligenz in der Ressourcenverwaltung, Fehlerdiagnose und Sicherheitsüberwachung könnten sich die Systeme selbst optimieren und dadurch effektiver zusammenarbeiten.
- Standardisierung und Interoperabilität:
- Die Entwicklung von gemeinsamen Standards und Protokollen wird es ermöglichen, dass Grid- und Cloud-Lösungen leichter integriert werden können, wodurch die Grenzen zwischen den beiden Ansätzen weiter verschwimmen.
Zusammenfassung
Sowohl Grid als auch Cloud Computing haben ihre spezifischen Stärken und Einsatzbereiche:
- Grid Computing eignet sich besonders für wissenschaftliche und technische Anwendungen, bei denen große, verteilte Rechenressourcen und Kooperation über mehrere Institutionen hinweg benötigt werden.
- Cloud Computing punktet mit Flexibilität, Elastizität und einem breiten Service-Angebot (IaaS, PaaS, SaaS), was es ideal für dynamische, webbasierte und geschäftskritische Anwendungen macht.
Durch die Kombination beider Ansätze können Unternehmen und Forschungseinrichtungen von einer optimierten Ressourcennutzung, Kosteneffizienz und erhöhter Agilität profitieren. Zukünftige Entwicklungen, wie die Integration von Edge Computing, serverlosen Architekturen und KI-gestützten Automatisierungslösungen, werden voraussichtlich zu einer weiteren Konvergenz und Verbesserung beider Technologien führen.
Diese umfassende Betrachtung bietet einen Überblick über die zentralen Aspekte, Gemeinsamkeiten und Unterschiede sowie die zukünftigen Trends im Bereich Grid und Cloud Computing.
Aufgabe 10.3: Datenmanagement
Aufgabenstellung
In den Vorlesungsfolien wurde gezeigt, dass in der Grid-Middleware gLite die Abbildung eines logischen Dateinamens auf die tatsächlichen Daten 10 Schritte erfordert (Folie 93 ff. DataManagement). Dabei werden von der Anfrage einer Datei bis zur Verwendbarkeit des Inhalts der Datei mehrere Dienste und Identifier genutzt. Beispiele hierfür sind der Logical File Name (LFN) oder die Transport URL.
Erstellen Sie ein Sequenzdiagramm für den Zugriff auf eine Datei im Kontext des gLite-Datenmanagements. Berücksichtigen Sie dabei folgende Objekte:
- Requester
- IO-Server
- File Catalog
- Replica Catalog
- Storage Resource Manager
- Storage Element
Akronyme Erklärt (LFN, GUID, SURL, TURL, SRM)
1. LFN (Logical File Name):
- Bedeutung: Logischer Dateiname. Ein vom Benutzer vergebener, sprechender Name für eine Datei, der unabhängig von ihrem physischen Speicherort ist.
- Relevanz: Ermöglicht es Benutzern, Dateien einfach zu identifizieren und darauf zuzugreifen, ohne sich um technische Details kümmern zu müssen.
- Beispiel:
simulation/2024/ATLAS/run001.root
Dieser LFN identifiziert beispielsweise ein Simulationsergebnis, ohne den konkreten Speicherort zu verraten.2. GUID (Globally Unique Identifier):
- Bedeutung: Global eindeutige Kennung. Eine eindeutige Nummer, die einer Datei oder einem Datenelement zugewiesen wird, um es global identifizierbar zu machen.
- Relevanz: Stellt sicher, dass jede Datei eindeutig identifiziert werden kann, unabhängig davon, wo sie gespeichert ist. Wichtig für die Datenverwaltung und Replikation.
- Beispiel:
123e4567-e89b-12d3-a456-426614174000
Selbst wenn zwei Dateien denselben LFN haben, garantiert diese GUID ihre eindeutige Identifizierung.3. SURL (Storage URL):
- Bedeutung: Speicher-URL. Eine URL, die den Speicherort einer Datei auf einem bestimmten Speichersystem angibt.
- Relevanz: Ermöglicht den Zugriff auf Dateien über verschiedene Speichersysteme hinweg.
- Beispiel:
srm://storage.grid.example.org:8443/dpm/grid.example.org/data/simulation/2024/run001.root
Diese SURL verweist direkt auf den physischen Speicherort der Datei in einem verteilten Speichersystem.4. TURL (Transport URL):
- Bedeutung: Transport-URL. Eine URL, die angibt, wie eine Datei von einem Speicherort zu einem anderen übertragen werden kann.
- Relevanz: Ermöglicht die effiziente Übertragung von Dateien zwischen verschiedenen Systemen und Standorten.
- Beispiel:
gsiftp://gridftp.grid.example.org:2811/pnfs/gridftp/data/simulation/2024/run001.root
Über diese TURL kann die Datei mittels GridFTP-Protokoll von einem Speicherort an einen anderen transportiert werden.5. SRM (Storage Resource Manager):
- Bedeutung: Speicherressourcen-Manager. Eine Komponente, die für die Verwaltung von Speicherressourcen zuständig ist, wie z. B. Speicherplatz, Bandbreite und Zugriffsrechte.
- Relevanz: Optimiert die Nutzung von Speicherressourcen und stellt sicher, dass Dateien effizient gespeichert und abgerufen werden können.
- Beispiel:
Ein SRM wie StoRM oder dCache SRM koordiniert den Zugriff auf die Dateien, prüft deren Verfügbarkeit und organisiert den Datenfluss zwischen unterschiedlichen Speichersystemen.Zusätzliche Akronyme und Begriffe:
- Storage Element: Eine physische Speichereinheit, z. B. eine Festplatte oder ein Bandlaufwerk.
- Beispiel: Ein Server in einem Rechenzentrum, der als Storage Element fungiert.
- File Catalog: Ein Verzeichnis, das Informationen über Dateien speichert, wie z. B. ihren LFN, GUID und Speicherort.
- Beispiel: Ein Eintrag im File Catalog könnte folgende Daten enthalten:
- LFN:
/simulation/2024/ATLAS/run001.root- GUID:
123e4567-e89b-12d3-a456-426614174000- SURL:
srm://storage.grid.example.org:8443/dpm/grid.example.org/data/simulation/2024/run001.root- Replica Catalog: Ein Verzeichnis, das Informationen über Replikate von Dateien speichert, d. h. Kopien derselben Datei an verschiedenen Speicherorten.
- Beispiel: Ein Replica Catalog listet für dieselbe GUID mehrere SURLs, z. B.:
- Replica 1:
srm://storage1.grid.example.org:8443/dpm/grid.example.org/data/simulation/2024/run001.root- Replica 2:
srm://storage2.grid.example.org:8443/dpm/grid.example.org/data/simulation/2024/run001.root- Virtual Organization: Eine Gruppe von Benutzern und Ressourcen, die zusammenarbeiten, um ein gemeinsames Ziel zu erreichen.
- Beispiel: Die Virtual Organization ATLAS im CERN Grid, in der Forscher aus verschiedenen Institutionen gemeinsam an der Datenauswertung arbeiten.
- Data Management: Der Prozess der Verwaltung von Daten, einschließlich Speicherung, Abruf, Übertragung und Replikation.
- Beispiel: Ein typischer Data-Management-Workflow umfasst:
- Registrierung: Eine Datei wird im File Catalog mit LFN und GUID registriert.
- Speicherung: Die Datei wird auf einem Storage Element abgelegt (SURL).
- Replikation: Der Replica Catalog wird aktualisiert, um alternative Kopien zu erfassen.
- Transfer: Bei Bedarf wird die Datei über eine TURL an den angeforderten Standort übertragen.
Kontextbezug:
Diese Akronyme und Komponenten sind entscheidend für die effiziente Datenverwaltung in Grid- und Cloud-Computing-Umgebungen. Sie ermöglichen es Benutzern, große Datenmengen zu speichern, zu verwalten und darauf zuzugreifen, unabhängig von ihrem physischen Speicherort. Die Verwendung von LFNs, GUIDs, SURLs und TURLs abstrahiert technische Details, vereinfacht den Datenzugriff und unterstützt durch SRMs die optimale Nutzung der Speicherressourcen sowie die Wahrung der Datenintegrität.
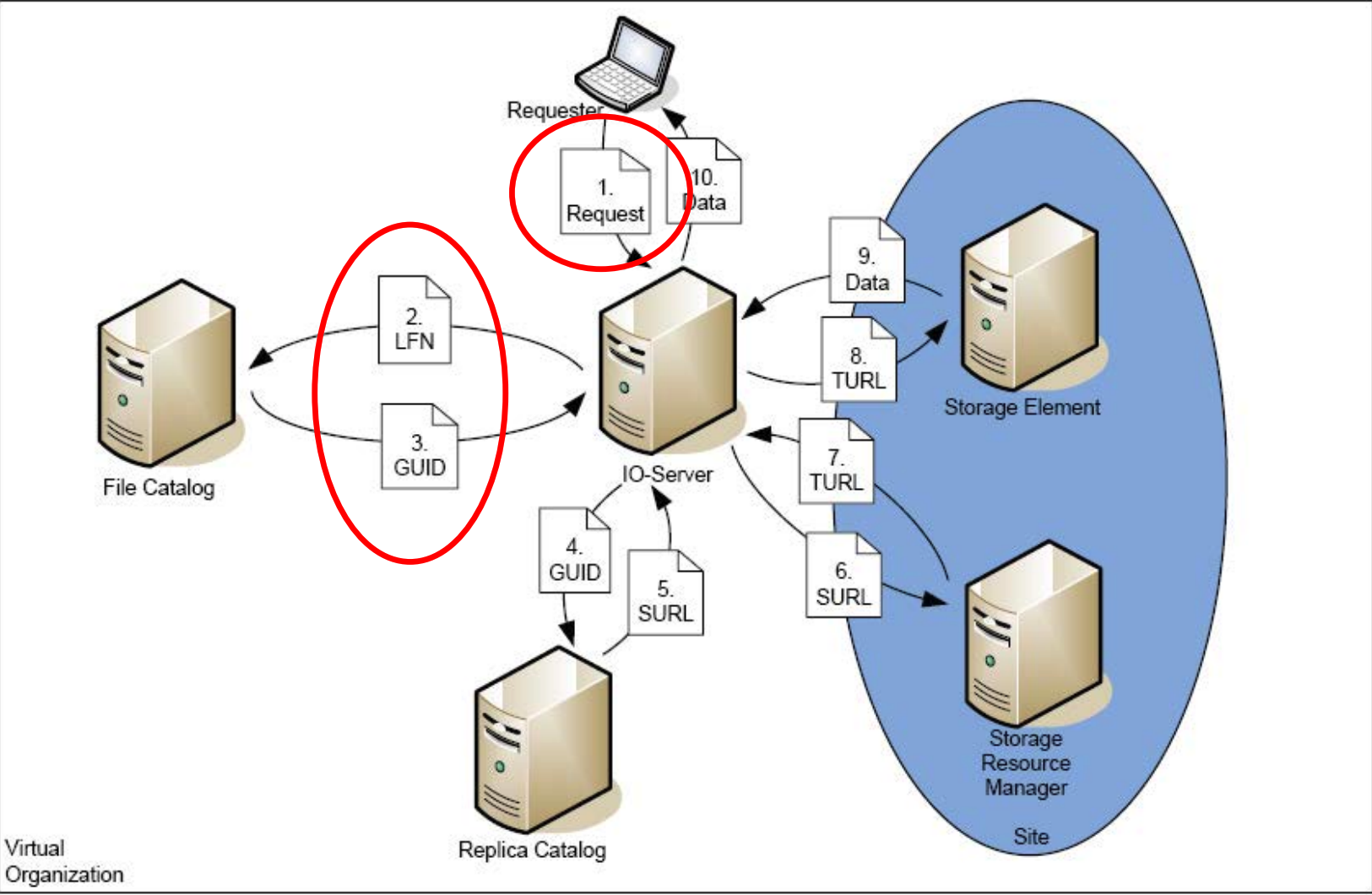
sequenceDiagram
autonumber
participant R as Requester
participant IO as IO-Server
participant FC as File-Catalog
participant RC as Replica-Catalog
box Site
participant SRM as Storage-Resource-Manager
participant SE as Storage-Element
end
R ->> IO: Request
IO ->> FC: LFN
FC -->> IO : GUID
IO ->> RC: GUID
RC -->> IO : SURL
IO ->> SRM: SURL
SRM -->> IO: TURL
IO ->> SE: TURL
SE -->> IO: Data
IO ->> R: Data
Erklärung der Schritte
Ablauf des Datenmanagements im gLite Grid
- Der Requester (Benutzer) initiiert eine Anfrage nach einer bestimmten Datei, indem er deren logischen Dateinamen (LFN) an den IO-Server sendet. Der LFN ist ein für Menschen lesbarer Name, der von der tatsächlichen Speicheradresse abstrahiert.
- Der IO-Server (Input/Output-Server) fungiert als Vermittler und leitet die LFN-Anfrage an den File Catalog weiter. Der File Catalog ist wie ein zentrales Verzeichnis, das LFNs ihren entsprechenden global eindeutigen Bezeichnern (GUIDs) zuordnet.
- Der File Catalog antwortet mit der GUID der angeforderten Datei. Die GUID ist eine eindeutige Kennung, die unabhängig vom Speicherort der Datei ist und somit die Basis für die weitere Suche bildet.
- Der IO-Server nutzt die GUID und fragt den Replica Catalog ab. Der Replica Catalog enthält Informationen darüber, wo verschiedene Kopien (Replikate) der Datei gespeichert sind, zusammen mit den entsprechenden Speicher-URLs (SURLs).
- Der Replica Catalog liefert eine oder mehrere SURLs zurück, die auf mögliche Speicherorte der Datei verweisen. Der IO-Server wählt eine geeignete SURL aus (z. B. basierend auf Nähe oder Verfügbarkeit).
- Mit der ausgewählten SURL kontaktiert der IO-Server den zuständigen Storage Resource Manager (SRM). Der SRM ist für die Verwaltung der Speicherressourcen zuständig und kennt die Details des Speicherorts.
- Der SRM antwortet mit einer Transport-URL (TURL). Die TURL enthält alle notwendigen Informationen für den Zugriff auf die Datei, einschließlich des spezifischen Protokolls und der Adresse des Storage Elements.
- Der IO-Server nutzt die TURL, um die Datei vom Storage Element abzurufen. Das Storage Element ist die tatsächliche Speichereinheit, auf der die Datei физически liegt.
- Das Storage Element sendet die angeforderte Datei an den IO-Server.
- Der IO-Server leitet die Datei an den Requester weiter. Der Requester erhält die angeforderte Datei und kann sie nun verwenden.
Warum ist das so kompliziert?
Diese komplexen Schritte sind notwendig, um die Herausforderungen des Datenmanagements in großen, verteilten Grid-Umgebungen zu bewältigen:
- Abstraktion: LFNs ermöglichen es Benutzern, Dateien einfach zu finden, ohne sich um technische Details kümmern zu müssen.
- Eindeutigkeit: GUIDs stellen sicher, dass jede Datei eindeutig identifiziert werden kann, auch wenn sie an verschiedenen Orten repliziert ist.
- Flexibilität: SURLs und TURLs ermöglichen den Zugriff auf Dateien über verschiedene Speichersysteme und Protokolle hinweg.
- Effizienz: SRMs optimieren die Nutzung von Speicherressourcen und sorgen für eine effiziente Datenübertragung.
- Skalierbarkeit: Die Architektur ist darauf ausgelegt, mit großen Datenmengen und einer Vielzahl von Benutzern umzugehen.
Aufgabe 10.4: Daten und Foster
Aufgabenstellung
In einer Virtuelle Organisation liegen die Daten in der Regel verteilt auf verschiedenen Systemen. Ihre Massendaten (im TeraByte-Bereich) wollen Sie in der Beluga Data Farm mit dem dort eingesetzten Krill-SRM verwalten.
Als Massenspeichersystem dient das Plankton Tape Archive. Das Krill-SRM setzt zudem einen Storage Resource Broker (Kaviar-SRB) ein, der für eine bessere Koordination bei Multi-File-Requests zwischen verschiedenen SRMs sorgen soll (siehe Abbildung 12).
Für die Mitglieder der VO ist die Data Farm eine Grid-Ressource, auf der diverse Dienste angeboten werden. Sie kann damit in Fosters Grid-Architektur eingebettet werden.
Ordnen Sie bitte in der folgenden Matrix die diversen Dienste den einzelnen „Foster-Ebenen“ zu.
| Foster-Ebene | GridFTP | Plankton Tape Archive | Krill-SRM | Kaviar-SRB |
|---|---|---|---|---|
| Fabric | ||||
| Connectivity | ||||
| Resource | ||||
| Collective |
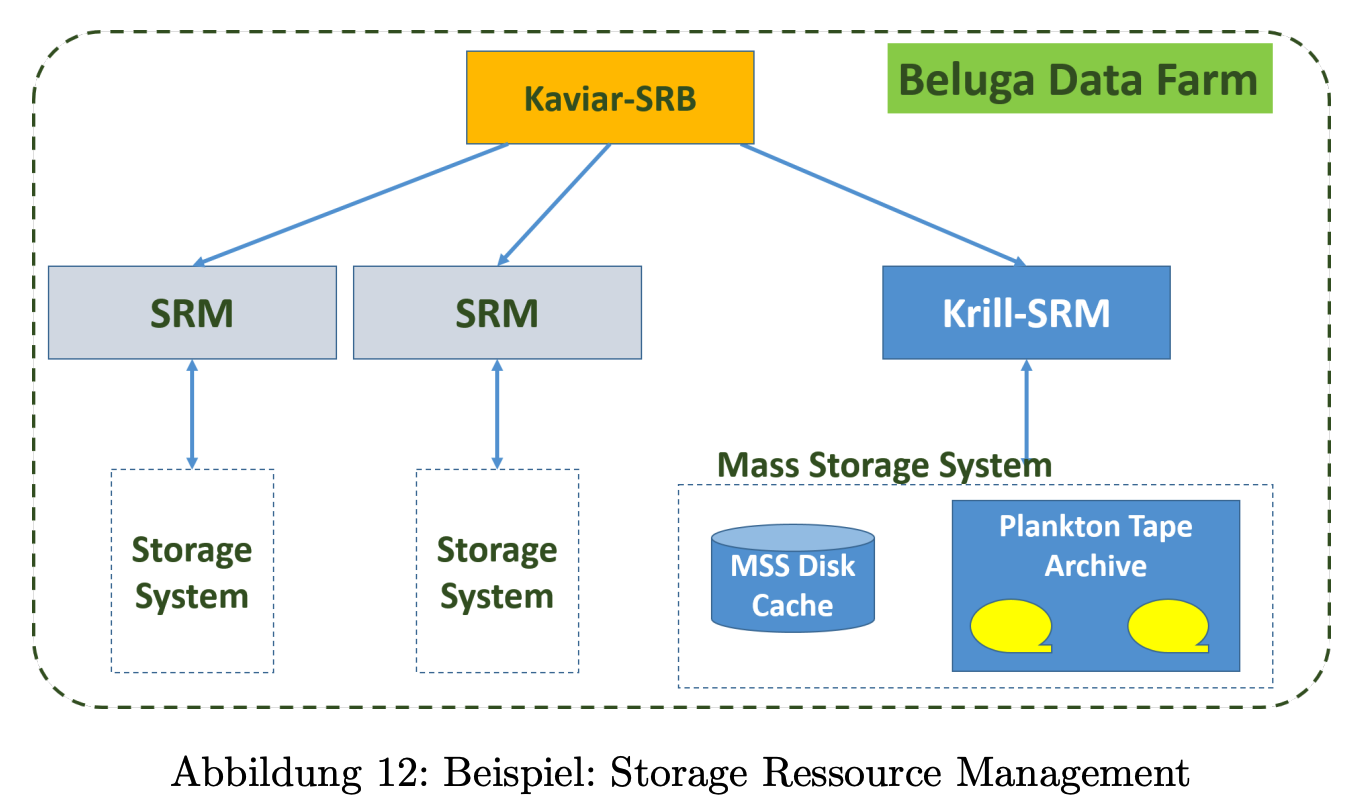
Überblick: GridFTP, Plankton Tape Archive, Krill-SRM & Kaviar-SRB
- GridFTP
- Funktion: Erweiterte FTP-Variante, speziell optimiert für den schnellen und sicheren Datentransfer in Grid-Umgebungen.
- Eigenschaften: Unterstützt parallele Datenströme, Drittanbieter-Transfers und bietet hohe Performance sowie Zuverlässigkeit.
- Einsatzgebiet: Übertragung großer Datenmengen zwischen verteilten Systemen.
- Plankton Tape Archive
- Funktion: Tape-basierte Archivierungslösung innerhalb des Grid-Ökosystems.
- Eigenschaften: Ermöglicht die langfristige Speicherung und Verwaltung von Daten auf Bandlaufwerken.
- Einsatzgebiet: Archivierung und Sicherung von Daten, insbesondere bei hoher Speicherdichte oder zur Langzeitaufbewahrung.
- Krill-SRM
- Funktion: Storage Resource Manager (SRM), der die Verwaltung und Koordination von Speicherressourcen übernimmt.
- Eigenschaften: Organisiert den Datenzugriff, regelt Ressourcenverteilung und optimiert die Speicherung in verteilten Umgebungen.
- Einsatzgebiet: Sicherstellung eines konsistenten und effizienten Datenzugriffs über heterogene Speichersysteme.
- Kaviar-SRB
- Funktion: Storage Resource Broker (SRB), der als Middleware verschiedene Speicherressourcen integriert.
- Eigenschaften: Bietet ein einheitliches Zugriffssystem für unterschiedliche Speicherorte und ermöglicht so eine nahtlose Datenverwaltung.
- Einsatzgebiet: Vereinheitlichter Datenzugriff und -management über diverse und verteilte Speichersysteme hinweg.
Dieses strukturierte Callout fasst kurz und prägnant die wesentlichen Funktionen, Eigenschaften und Einsatzbereiche der vier Komponenten zusammen und verdeutlicht, wie sie im Kontext von Grid-Datenmanagement zusammenwirken.
Lösung
Um die Dienste GridFTP, Plankton Tape Archive, Krill-SRM und Kaviar-SRB den Foster-Ebenen zuzuordnen, betrachten wir die Definitionen und Funktionen der einzelnen Ebenen. Die Foster-Architektur besteht aus vier Ebenen: Fabric, Connectivity, Resource und Collective.
Hier ist die Zuordnung der Dienste zu den Foster-Ebenen, basierend auf den Informationen aus den Quellen:
Fabric: Diese Ebene beinhaltet die grundlegenden Ressourcen, die von einem Grid-System verwaltet werden.
- Plankton Tape Archive: Als Massenspeichersystem stellt es die physische Speicherkapazität dar und gehört somit zur Fabric-Ebene.
Connectivity: Diese Ebene beinhaltet die Kernprotokolle, die für den Zugriff und die Nutzung der Ressourcen notwendig sind.
- (Kein direkter Eintrag für diese Ebene in dieser Zuordnung)
Resource: Diese Ebene beinhaltet die Verwaltung einzelner Ressourcen, wie z. B. Speicher.
- GridFTP: Als Dienst für den schnellen und zuverlässigen Datentransfer zwischen verschiedenen Grid-Ressourcen gehört GridFTP zur Resource-Ebene, da es den Zugriff auf Speicherressourcen verwaltet.
- Krill-SRM: Der Krill-SRM (Storage Resource Manager) dient der Verwaltung des Speicherplatzes und der Daten. Er stellt sicher, dass Speicherressourcen den Benutzern der virtuellen Organisation (VO) zur Verfügung stehen und korrekt genutzt werden können.
Collective: Diese Ebene beinhaltet Dienste, die mehrere Ressourcen koordinieren und das Teilen von Ressourcen in dynamischen, multi-institutionellen, virtuellen Organisationen ermöglichen.
- Kaviar-SRB: Als Storage Resource Broker (SRB) koordiniert Kaviar Multi-File-Requests zwischen verschiedenen SRMs. Dies verbessert die Koordination und Effizienz bei der Nutzung verteilter Speicherressourcen innerhalb der VO.
Zusammengefasst ergibt sich folgende Matrix:
Foster-Ebene GridFTP Plankton Tape Archive Krill-SRM Kaviar-SRB Fabric X Connectivity Resource X X Collective X
Aufgabe aus Altklausur
Aufgabenstellung
Ein ehemaliger Studienkollege, Thomas Meinzer, hat sich als Cloud-Provider einen Namen gemacht und tritt als zuverlässiger Partner auf. Der Fokus seines Service-Portfolios liegt beim Bereitstellen von Software as a Service (SaaS). Obwohl er viel in seine Hardware investiert hatte, kommt er zunehmend an Auslastungsgrenzen. Leider kann er aktuell nicht mehr Hardware-Nodes in seine Cloud vor Ort integrieren, da der Energieverbrauch seines kleinen Rechenzentrums das Maximum erreicht hat.
Um aber seinen Kunden weiter leistungsstarke Services anzubieten, kommt er auf Sie zu und fragt, ob Sie ihm helfen können, da er sich erinnern kann, dass Sie auch einen guten Draht zu Walter Roller hatten, welcher sich auch als Cloud-Provider etabliert hat. Sie haben schon seit langem mit dem Gedanken gespielt, als Cloud-Broker in das Geschäft einzusteigen und bereiten dies nun konkret vor.
a) Grenzen Sie zunächst SaaS zu IaaS und PaaS ab. Wo liegt der größte Mehrwert für den Kunden?
- IaaS (Infrastructure as a Service)
- Bereitstellung:
- Grundlegende IT-Infrastruktur wie virtuelle Maschinen, Speicherplatz und Netzwerke.
- Nutzer konfiguriert und verwaltet die Ressourcen eigenständig.
- Beispiel:
- Cloud-Server (z. B. ein Droplet bei DigitalOcean), auf dem Betriebssysteme, Anwendungen und weitere Dienste selbst installiert werden.
- Mehrwert:
- Maximale Flexibilität.
- Hohe Kontrolle und individuelle Anpassung der Infrastruktur.
- Bereitstellung:
- PaaS (Platform as a Service)
- Bereitstellung:
- Vorgefertigte Entwicklungsplattform, auf der Anwendungen entwickelt, getestet und ausgeführt werden können.
- Keine Notwendigkeit, sich um die zugrunde liegende Infrastruktur zu kümmern.
- Beispiel:
- Google App Engine, das eine Umgebung für die schnelle Bereitstellung von Anwendungen bietet.
- Mehrwert:
- Reduzierter Verwaltungsaufwand.
- Schnellere Entwicklungszeiten.
- Keine Sorge um Betriebssysteme, Middleware oder Netzwerkkonfigurationen.
- Bereitstellung:
- SaaS (Software as a Service)
- Bereitstellung:
- Vollständig gehostete Softwarelösung, die über das Internet zugänglich ist.
- Der Anbieter übernimmt Installation, Updates und Wartung.
- Beispiel:
- Microsoft Office 365, das Anwendungen wie Word, Excel und Outlook direkt in der Cloud anbietet.
- Mehrwert:
- Minimaler Verwaltungsaufwand.
- Kontinuierliche automatische Updates.
- Hohe Verfügbarkeit und flexibler Zugriff von überall.
- Nutzer kann sich vollständig auf seine Kernaufgaben konzentrieren.
- Bereitstellung:
Ausführlicher
- IaaS (Infrastructure as a Service)
- Der Nutzer erhält eine grundlegende IT-Infrastruktur, wie virtuelle Maschinen, Speicherplatz oder Netzwerke, die er selbst konfigurieren und verwalten muss. Ein Beispiel für IaaS ist ein Cloud-Server (z. B. ein Droplet bei DigitalOcean), auf dem der Nutzer Betriebssysteme, Anwendungen und weitere Dienste selbst installieren kann.
- Mehrwert: Maximale Flexibilität und Kontrolle über die Infrastruktur, da Anpassungen nach individuellen Bedürfnissen möglich sind.
- PaaS (Platform as a Service)
- Hier wird dem Nutzer eine vorgefertigte Plattform bereitgestellt, auf der er Anwendungen entwickeln, testen und ausführen kann, ohne sich um die darunterliegende Infrastruktur kümmern zu müssen. Ein Beispiel ist Google App Engine, das Entwicklern eine Umgebung zur Verfügung stellt, um Anwendungen bereitzustellen, ohne sich um Serverwartung oder Skalierung zu kümmern.
- Mehrwert: Reduzierter Verwaltungsaufwand und eine schnellere Entwicklungszeit, da sich der Nutzer nicht um Betriebssysteme, Middleware oder Netzwerkkonfigurationen kümmern muss.
- SaaS (Software as a Service)
- Hier wird dem Nutzer eine vollständig gehostete Softwarelösung bereitgestellt, die er über das Internet nutzt. Der Anwender muss keine Software lokal installieren, aktualisieren oder warten, da all diese Aufgaben vollständig vom Anbieter übernommen werden. Ein Beispiel ist Microsoft Office 365, das Anwendungen wie Word, Excel oder Outlook direkt in der Cloud anbietet.
- Mehrwert: Der Nutzer profitiert von minimalem Verwaltungsaufwand, kontinuierlichen Updates und hoher Verfügbarkeit, sodass er sich ganz auf seine Aufgaben konzentrieren kann, während der Anbieter für einen reibungslosen Betrieb sorgt.
b) Welcher Cloud-Broker Typ passt auf das beschriebene Szenario? Erklären Sie dieses mit einem aussagekräftigen Beispiel.
Typen von Cloud-Brokern
1. Vermittlung („Service Intermediation“)
Beim Vermittlungsmodell erweitert der Cloud-Broker den bestehenden Service eines Providers um zusätzliche, wertschöpfende Funktionen. Er fungiert als Ergänzung zum Basisangebot und integriert beispielsweise:
- Identitätsmanagement: Zentralisierte Verwaltung und Authentifizierung von Nutzerkonten.
- Performance Reporting: Ausführliche Leistungsberichte zur Analyse und Optimierung der Ressourcennutzung.
- Erweiterte Sicherheitsfeatures: Zusätzliche Schutzmechanismen, die über die Standardsicherheit hinausgehen.
Beispiel: Ein Unternehmen nutzt einen Cloud-Dienst für Datenspeicherung. Der Broker ergänzt diesen Service durch ein Identitätsmanagement-System, das die Zugriffskontrolle und die Einhaltung von Compliance-Richtlinien verbessert.
2. Aggregierung („Service Aggregation“)
Bei der Aggregierung kombiniert der Cloud-Broker mehrere Dienste zu einem neuen, integrierten Angebot. Dabei übernimmt er die technische und sicherheitstechnische Integration der unterschiedlichen Services, etwa durch:
- Datenintegration: Zusammenführung von Informationen aus diversen Quellen zu einem konsistenten Datenpool.
- Sicherstellung sicherer Datenströme: Gewährleistung eines reibungslosen und geschützten Datenaustauschs zwischen Cloud-Nutzern und den verschiedenen Cloud-Providern.
Beispiel: Ein Broker fasst Compute-, Storage- und Sicherheitsdienste verschiedener Anbieter zusammen und bietet so eine umfassende Cloud-Lösung, die den spezifischen Anforderungen eines Unternehmens gerecht wird.
3. Service Arbitrage
Der Service-Arbitrage-Ansatz ähnelt der Aggregierung, ist jedoch noch flexibler. Der Broker wechselt je nach aktuellen Leistungs- oder Kostenvorgaben dynamisch zwischen verschiedenen Anbietern. So wird stets der bestmögliche Service unter den aktuellen Marktbedingungen gewählt.
Beispiel: Bei schwankender Nachfrage entscheidet der Broker, ob es wirtschaftlicher ist, zusätzliche Ressourcen von einem günstigeren Anbieter zu mieten oder die vorhandenen Kapazitäten zu optimieren – stets basierend auf dem aktuellen Preis-Leistungs-Verhältnis.
Diese drei Ansätze zeigen, wie Cloud-Broker Unternehmen dabei unterstützen, maßgeschneiderte und effiziente Cloud-Lösungen zu realisieren.
Das Szenario passt zum Aggregationsmodell, weil der Broker verschiedene Dienste zu einem festen, integrierten Angebot zusammenführt. Es handelt sich nicht um Service Arbitrage, da hier keine dynamische Selektion zwischen unterschiedlichen Anbietern stattfindet, sondern die Leistungen dauerhaft gebündelt werden.
Beispiel:
Ein Unternehmen benötigt Rechenleistung, Speicher und Sicherheitsfunktionen aus unterschiedlichen Clouds. Der Broker bündelt diese Services zu einer nahtlos funktionierenden Gesamtlösung, sodass das Unternehmen nicht mehrere Verträge verwalten muss.
c) Sie haben in der Vorlesung zwei weitere Cloud-Broker Typen kennengelernt. Erstellen Sie für beide ein konkretes Szenario. Gehen Sie dabei auf den Kunden, die Cloud-Provider und einen möglichen Service ein, der jeweils auf die beiden Typen passt.
- Service Intermediation
- Beschreibung:
Der Cloud-Broker erweitert hier einen bestehenden Service eines Cloud-Providers um zusätzliche Funktionen, die dem Kunden einen direkten Mehrwert bieten. Der zugrunde liegende Basisservice bleibt erhalten, während durch die zusätzlichen Funktionen die Anforderungen an Sicherheit, Compliance oder Performance optimiert werden. - Beispiel:
Ein Unternehmen nutzt einen Cloud-Dienst eines etablierten Providers zur Speicherung von sensiblen Anmeldedaten. Der Cloud-Broker ergänzt diesen Service um zusätzliche Sicherheitsfunktionen – etwa durch die Integration eines erweiterten Authentifizierungs- und Autorisierungssystems. Dadurch werden strenge Compliance-Richtlinien erfüllt, ohne dass der Kunde den Basisdienst wechseln muss.
- Beschreibung:
- Service Aggregation
- Beschreibung:
Beim Aggregationsmodell kombiniert der Cloud-Broker mehrere einzelne Cloud-Dienste zu einem neuen, integrierten Gesamtangebot. So werden die Vorteile verschiedener Provider in einem Service zusammengeführt, was dem Kunden eine maßgeschneiderte Lösung bietet. - Beispiel:
Ein Unternehmen möchte seine Web-Anwendungen auf einem leistungsstarken Hyperscaler (z. B. Hyperscaler A) hosten, gleichzeitig aber aus Kostengründen die Daten auf einem anderen Provider (z. B. Hyperscaler B) speichern. Der Cloud-Broker integriert diese beiden Angebote so, dass die Anwendung reibungslos läuft und gleichzeitig Kostenoptimierungen genutzt werden können.
- Beschreibung: