Prinzip
In den letzten beiden Kapiteln haben wir einfache Anwendungen der Bayes-Formel kennen gelernt. Wir erweitern diese Anwendung nun auf allgemeinere stochastische Modelle. Um daraus Schlüsse zu ziehen, verwenden wir das Bayes-Prinzip
Bayes-Prinzip
Bayesianische Inferenz
Im Folgenden wiederholen und verallgemeinern wir das Vorgehen in unseren bisherigen Beispielen:
- Wir beobachten Daten , die aus einem Zufallsprozess entstanden sind.
- Die sind Realisierungen einer Zufallsvariable .
- hat eine Verteilung mit (Daten-)Dichte (Likelihood) .
- Wir kennen die Datendichte aber nicht vollständig, sondern nur bis auf Parameter :
- ist unbekannt und die Information über lässt sich in Form einer Dichte darstellen
- Vor der Beobachtung (a priori) ist unsere Information ausgedrückt durch die Priori-Dichte
- Durch Beobachtung erhalten wir mehr Information, ausgedrückt durch die a posteriori-Dichte
Bisher waren und eindimensional, im Folgenden können sie aber auch mehrdimensional sein!
Aufgaben in der Bayesianischen Inferenz
- Festlegung des statistischen Modells für und damit der Datendichte (Likelihood)
- Festlegung des a priori-Wissens über , also der Priori-Dichte
- Berechnung der Posteriori
Bayes-Prinzip
- Die Dichte der Posteriori-Verteilung erhalten wir über die Bayes-Formel:
Bayes-Prinzip Alle Schlüsse werden nur aus der Posteriori-Verteilung gezogen.
- Die Posteriori enthält alle Informationen über nach der Beobachtung.
- Umso mehr Informationen die Daten über enthalten, umso weniger unsicher sind wir über : Die Varianz der Posterioriverteilung ist kleiner, die Dichtefunktion konzentriert sich in einem (oder mehreren) Bereichen.
Was machen wir mit der Posteriori?
- Grundsätzlich gilt: Die komplette Posteriori ist wichtig. Wenn möglich, sollten wir diese komplett darstellen – bei hochdimensionalen Parametern ist dies aber schwierig. Hier bietet es sich an, jeden Parameter einzeln anzuschauen; genauer: die marginale Posteriori von zu betrachten.
Aus der Posteriori können wir dann folgende Schlüsse ziehen:
- Punktschätzer: (wir kennen den Posterior-Erwartungswert, außerdem gibt es den Maximum-a-Posteriori-Schätzer/Posteriori-Modus und den Posteriori-Median)
- Intervallschätzer
- Tests
- Modellvergleich
- Prädiktion
Zusammenfassung
Zusammenfassung des Bayes-Prinzips
Bayesianische Inferenz
Bayesianische Inferenz ist ein Ansatz in der Statistik, bei dem Wissen über eine unbekannte Größe (Parameter ) durch beobachtete Daten verbessert wird. Dies geschieht durch den Einsatz von Wahrscheinlichkeitsmodellen, die wie folgt definiert sind:
- Es werden Datenpunkte beobachtet, die aus einem Zufallsprozess stammen und Realisierungen einer Zufallsvariable sind.
- Jede folgt einer Verteilung, deren Form durch die Parameter bestimmt wird: .
- Vor der Datenerhebung besteht eine anfängliche Einschätzung des Parameters , ausgedrückt durch die Priori-Dichte .
- Nach der Datenerhebung wird diese Einschätzung durch die Posteriori-Dichte aktualisiert, welche mittels der Bayes-Formel berechnet wird:
Aufgaben und Verwendung der Posteriori
- Statistisches Modell festlegen: Auswahl von und .
- Posteriori berechnen: Diese enthält alle Informationen über nach dem Einbezug der Daten und wird für alle weiteren Schlüsse verwendet.
- Analyse der Posteriori: Bei mehrdimensionalen betrachtet man oft die marginale Posteriori jedes Parameters .
Anwendungen der Posteriori
Aus der Posteriori lassen sich verschiedene statistische Schlüsse ziehen, darunter:
- Punktschätzer: Berechnung des Erwartungswertes, des Maximum-a-Posteriori-Schätzers und des Medians.
- Intervallschätzer: Bestimmung von Konfidenzintervallen.
- Tests: Durchführung statistischer Hypothesentests.
- Modellvergleich: Vergleich unterschiedlicher statistischer Modelle.
- Prädiktion: Vorhersage zukünftiger Beobachtungen basierend auf dem Modell.
Zusammengefasst ermöglicht das Bayes-Prinzip eine systematische Aktualisierung des Wissens über einen Parameter durch die Kombination von Priori-Information und Daten, wobei die Posteriori-Dichte als Grundlage für alle weiteren statistischen Analysen dient.
Prioris
Ein wichtiger Baustein der Bayes-Inferenz ist die Wahl der Prioris. Schauen wir uns Möglichkeiten zur Wahl der Priori an und kommen dazu zurück zum
Beta-Binomial-Modell
Lernziele
- Konstruktion konjugierter Prioris
- Anwendung und Kritik subjektiver Prioris
- Konstruktion einfacher nicht-informativer Prioris
Konjugierte Prioris
Wir hatten im Beispiel mit den Billardkugeln festgestellt, dass die Kombination von Binomialverteilung der Daten und Gleichverteilung als Priori gut zusammen passt: Wir erhalten eine bekannte Verteilung als Posteriori.
Allgemein definieren wir: Eine Familie von Verteilungen auf heißt konjugiert, zu einer Dichte , wenn für jede Priori auf die Posteriori ebenfalls zu gehört
Vereinfacht Gesagt
Konjugierte Prioris sind spezielle Priori-Verteilungen in der Bayesianischen Statistik, die die Berechnung der Posteriori-Verteilung vereinfachen. Wenn eine Priori-Verteilung konjugiert zur Likelihood-Funktion der Daten ist, bleibt die Form der Posteriori-Verteilung innerhalb derselben Familie von Verteilungen. Das bedeutet, dass sowohl die Priori als auch die Posteriori den gleichen Typ von Verteilung aufweisen, was die Analyse und Berechnungen einfacher macht.
Beispiel nach Bayes
Im Beispiel der Billardkugeln hatten wir die Gleichverteilung als Spezialfall der Betaverteilung als Priori und die Betaverteilung als Posteriori.
- Anzahl der Kugeln rechts von der weißen Kugel:
- Priori-Annahme für : mit
Wir nennen dieses Modell Beta-Binomial-Modell (Beta-Priori und Binomial-Datenmodell). Im Folgenden benutzen wir ganz allgemein die Parameter und in der Beta-Priori und werden dann auch andere Werte für die Priori-Parameter zulassen.
Man erkennt die Konjugiertheit am ähnlichen Aufbau von Datendichte (eine Funktion in ) und Priori, bezogen auf den unbekannten Parameter (wir betrachten hier nur jeweils den Kern der Dichte, lassen also Konstanten weg):
Zusammen also:
Posteriori-Parameter
- Die Posteriori-Verteilung von ist also eine Beta-Verteilung mit und . Die Parameter der Posterioriverteilung, also die Posteriori-Parameter setzen sich jeweils aus Informationen der Priori und der Datendichte zusammen.
- Allgemein fasst die Posteriori Informationen aus der Priori und der Datendichte zusammen.
- Hier ist die Summe der Priori-Parameter und der Anzahl an Erfolgen . Entsprechend ist die Summe des Priori-Parameters und der Anzahl an Misserfolgen .
Rückschluss auf die Priori-Parameter
- Das heißt also, wenn wir um eins erhöhen, ergibt sich für die Posteriori das selbe Ergebnis, wie wenn man die Anzahl der Erfolge um eins erhöht.
- kann also in gewisser Weise auch die Priori-Anzahl an Erfolgen interpretiert werden, entsprechend ist die Priori-Anzahl an Misserfolgen.
Vereinfacht Gesagt
Das Konzept der konjugierten Prioris ist ein zentrales Element in der Bayesianischen Statistik, das insbesondere die Berechnung der Posteriori-Verteilung vereinfacht. Konjugierte Prioris sind speziell ausgewählte Priori-Verteilungen, die dazu führen, dass die Posteriori-Dichte der gleichen Verteilungsfamilie angehört wie die Priori-Dichte. Dies bedeutet, dass wenn eine Priori-Verteilung konjugiert zur Likelihood-Funktion der Daten ist, die resultierende Posteriori-Verteilung denselben Typ von Verteilung aufweist wie die Priori, was mathematische Berechnungen und statistische Analysen erleichtert.
Beispiel: Das Beta-Binomial-Modell
In einem anschaulichen Beispiel mit Billardkugeln nutzen wir eine Betaverteilung als Priori und eine Binomialverteilung als Modell für die Daten. Dieses Zusammenwirken wird als Beta-Binomial-Modell bezeichnet:
- Nehmen wir an, die Anzahl der Kugeln rechts von einer weißen Kugel folgt einer Binomialverteilung .
- Die Priori-Annahme für die Wahrscheinlichkeit , dass eine Kugel rechts von der weißen Kugel liegt, wird als Betaverteilung modelliert: , wobei wir zunächst setzen, was einer Gleichverteilung entspricht.
Die Binomialverteilung für die Daten und die Betaverteilung für die Priori sind konjugiert, was mathematisch bedeutet:
- Die Likelihood-Funktion hat die Form .
- Die Priori-Dichte wird als angenommen.
- Multiplizieren wir diese beiden, erhalten wir die Posteriori-Dichte: .
Schlussfolgerungen aus der Posteriori
Die Posteriori-Verteilung nach Beobachtung der Daten ist wieder eine Betaverteilung, Beta, mit den neuen Parametern:
- (Summe aus der Anzahl der Erfolge und dem Priori-Parameter )
- (Summe aus der Anzahl der Misserfolge und dem Priori-Parameter )
Diese Parameteraktualisierung zeigt, wie Informationen aus der Priori-Verteilung (unsere Vorannahmen) und der Likelihood (Informationen aus den neuen Daten) in der Posteriori-Verteilung kombiniert werden. Die Priori-Parameter und können dabei als hypothetische Anzahl an Erfolgen bzw. Misserfolgen vor den neuen Beobachtungen interpretiert werden. Diese Interpretation erleichtert das Verständnis dafür, wie Vorwissen und neue Daten in der Bayesianischen Analyse zusammenfließen.
Quiz zu konjugierten Prioris
Sei Erlang-verteilt mit unbekanntem Parameter und bekanntem . Die Erlang-Verteilung ergibt sich zum Beispiel als Summe von unabhängigen Wartezeiten. Die Dichte der Erlang-Verteilung ist:
Info
Die Erlang-Verteilung wird verwendet, um die Verteilung von Wartezeiten zu beschreiben, wenn mehrere Ereignisse eintreten müssen. Sie ist eine Verallgemeinerung der Exponentialverteilung, bei der unabhängige Ereignisse mit der gleichen Rate eintreten müssen, bevor das beobachtete Ereignis auftritt.
Was ist die konjugierte Priori-Verteilung für
\lambda?
- Gamma-Verteilung mit
- Exponential-Verteilung mit
- Beta-Verteilung mit
Lösung
p(\lambda) \propto \lambda^{a-1} \exp(-b\lambda)Erklärung: Die Gamma-Verteilung ist die konjugierte Priori-Verteilung für den Parameter einer Erlang-Verteilung, da ihre Form ermöglicht, dass die Posteriori-Verteilung wieder eine Gamma-Verteilung ist, was die Berechnungen vereinfacht.
Sei -verteilt und die Priori-Verteilung
Wie ist die Posteriori-Verteilung von
\lambda|x?
- Ga
- Erlang
- Ga
- Ga
Lösung
(a+n, b+x)Erklärung: Bei der Erlang-Verteilung von mit und der Priori-Verteilung summiert sich der Parameter der Gamma-Priori um (weil Ereignisse zur Likelihood beitragen) und der Parameter um (die beobachtete Summe der Wartezeiten), um die Posteriori-Parameter und zu bilden. Dies stellt die natürliche Aktualisierung im Rahmen der Bayes’schen Statistik dar und behält die Form der Gamma-Verteilung bei, was Rechnungen vereinfacht.
Erlang-Verteilung und die Posteriori
Erlang-Verteilung und ihre Posteriori-Analyse
Die Erlang-Verteilung ist eine spezielle Form der Gamma-Verteilung und wird oft verwendet, um die Summe von mehreren unabhängigen, identisch exponentialverteilten Wartezeiten zu beschreiben. Diese wird insbesondere in der Warteschlangentheorie und Zuverlässigkeitstechnik angewendet. Die Erlang-Verteilung ist definiert durch zwei Parameter: die Form , welche die Anzahl der Ereignisse angibt, und die Rate , welche die Rate dieser Ereignisse darstellt.
Mathematische Definition
Die Dichte der Erlang-Verteilung, Erlang, ist gegeben durch:
Hierbei ist die Summe der Wartezeiten, und der Parameter muss eine ganze Zahl sein.
Bayesianische Analyse
Wenn erlang-verteilt mit bekannten und unbekanntem ist und eine Gamma-Priori-Verteilung hat, ergibt die bayesianische Analyse eine Posteriori-Verteilung für , die auch eine Gamma-Verteilung ist.
Posteriori-Verteilung
Die Parameter der Posteriori-Verteilung werden aktualisiert zu:
- (Formparameter): Erhöht um die Anzahl der Ereignisse , da jedes Ereignis als “Erfolg” im Sinne des Bayes’schen Lernens zählt.
- (Ratenparameter): Erhöht um die beobachtete Summe der Wartezeiten , da in der Erlang-Verteilung die Rate dieser Wartezeiten darstellt und eine höhere Summe der Wartezeiten eine höhere Rate impliziert, die für die Berechnung der neuen Erwartung von benötigt wird.
Fazit
Diese Analyse ist zentral für Anwendungen, wo die Verteilung von Wartezeiten in Prozessen (wie Telekommunikationsnetzwerken oder Fertigungsstraßen) modelliert werden muss und wo Parameter unsicher sind und aus Daten gelernt werden sollen.
Informative und subjektive Priori
Wir können also in die Priori-Verteilung “Information reinstrecken”. Und zwar theoretisch beliebig viel!
Zu viel Priori-Information
Nehmen wir im Billard-Beispiel als Priori und rollen dann zehn rote Kugeln, die alle links von der weißen Kugel zum Liegen kommen. Die Posteriori ist dann und die Posteriori-Dichte sieht so aus:
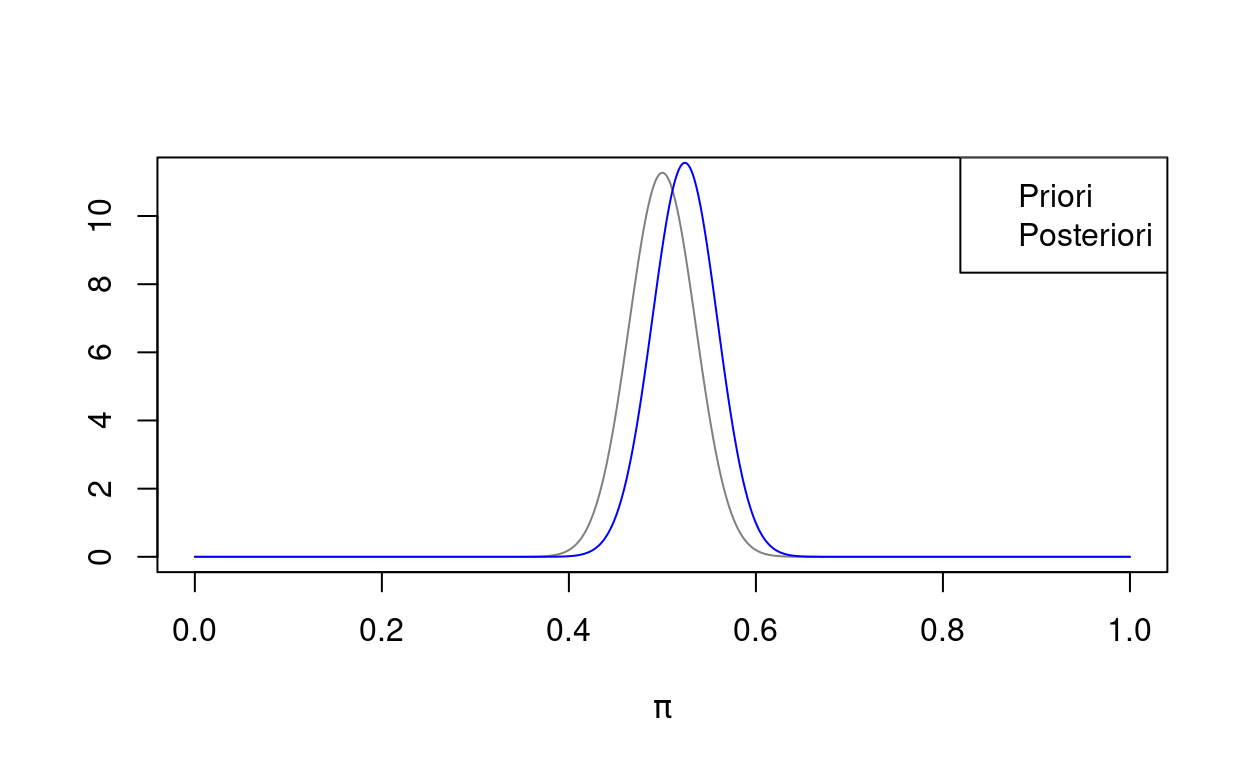
Die Posteriori unterscheidet sich auch kaum von der Priori, obwohl die Daten darauf hindeuten, dass die weiße Kugel weit rechts liegt.
Kritik an der Bayes-Inferenz
Die Möglichkeit, mit der Priori die Posteriori – und damit das Ergebnis – weitgehend festzulegen, ist traditionell ein großer Kritikpunkt an der Bayes-Inferenz. Eine derartige Vorfestlegung des Ergebnisses entspricht natürlich nicht wissenschaftlichen Grundsätzen.
Als Ausweg daraus kann man nicht informative Priors verwenden. Dafür werden wir uns den Begriff der Information noch genauer ansehen müssen.
Ein weiterer Anwendungsbereich der Bayes-Statistik liegt aber genau in der Nutzung von Vorwissen. Dieses kann zum Beispiel aus vorherigen Beobachtungen stammen – wir sprechen von sequentiellem Lernen, siehe dazu das Frosch-Beispiel – oder aus anderen Quellen, z.B. Expertenwissen.
Ein dritter Ansatzpunkt ist, die Priors als Teil der Modellierung zu verwenden. Zum Beispiel in dem man Parameter absichtlich Richtung Null drückt oder Abhängigkeiten zwischen Parametern berücksichtigt. Insbesondere in hochdimensionalen, eventuell überparametrisierten Modellen ist dies hilfreich. Dazu später mehr.
Nichtinformativen Priori
Im Beispiel der Billardkugeln hatten wir die Priori-Parameter und als Priori-Erfolge bzw. Priori-Misserfolge interpretiert. Intuitiv heißt keine Information, dass und .
Priori ohne Vorinformation
Setzen wir und in den Kern der Beta-Verteilung ein, erhalten wir die sogenannte Haldane-Priori:
Form der Haldane-Priori
Der Verlauf dieser Dichte, wie unten dargestellt, zeigt deutlich die Singularitäten an den Rändern bei 0 und 1.

Allerdings existiert das Integral , was zeigt, dass es keine echte Dichtefunktion ist, da das Integral einer Dichte immer 1 sein muss.
Die Haldane-Priori kann man herleiten als Grenzfall einer Beta-Verteilung mit und .
Uneigentliche Verteilungen
Das die Haldane-Priori keine Dichte hat, ist aber (erstmal) kein Problem! Wir verwenden diese uneigentliche Verteilung trotzdem.
Allgemein definieren wir eine uneigentliche oder impropere Verteilung mit Dichte wie folgt:
- für alle (wie bei jeder Dichte)
- (“eigentlich” müsste das Integral gleich 1 sein)
Posteriori bei uneigentlicher Verteilung
Im Billard-Beispiel haben wir - die Verteilung setzen wir hier in Anführungszeichen, denn die Priori ist eigentlich keine Beta-Verteilung. Trotzdem entspricht sie von der Form her der konjugierten Priori. Es gilt also für die Posteriori in diesem Fall:
Dies entspricht der Dichte einer Beta-Verteilung, wenn und , also wenn wir mindestens einen Erfolg und mindestens einen Misserfolg beobachtet haben.
Implikationen
- Aus einer uneigentlichen Posterioriverteilung können wir keine Schlüsse ziehen: weder können wir eine Posterioriwahrscheinlichkeit berechnen noch einen Posteriori-Erwartungswert.
- Die uneigentliche Priori führt aber im Regelfall zu einer eigentlichen oder properen Posterioriverteilung, aus der wir Schlüsse ziehen können.
- Nur in Ausnahmefällen kann eine uneigentliche Posterioriverteilung resultieren – dies muss man im Einzelfall überprüfen.