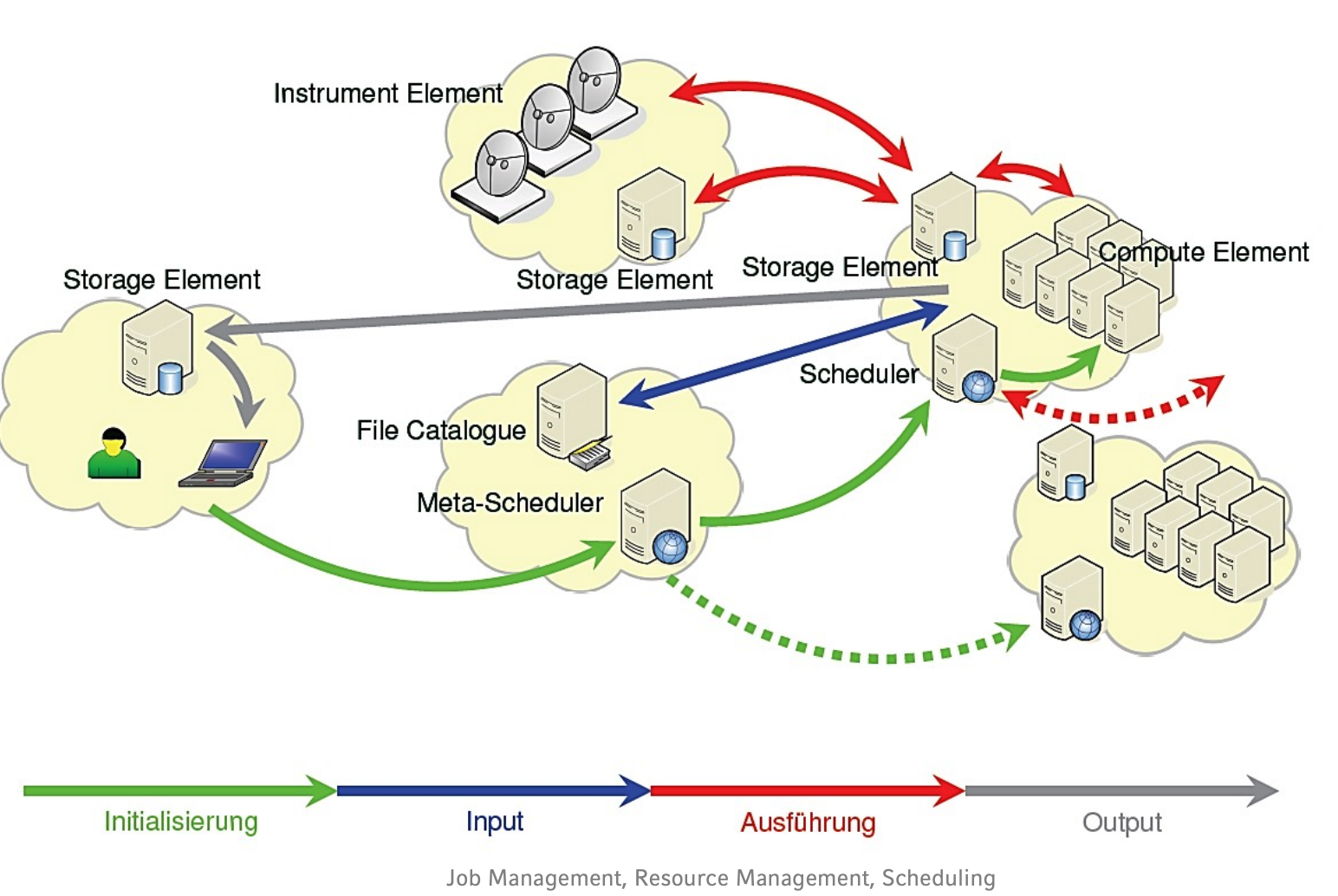
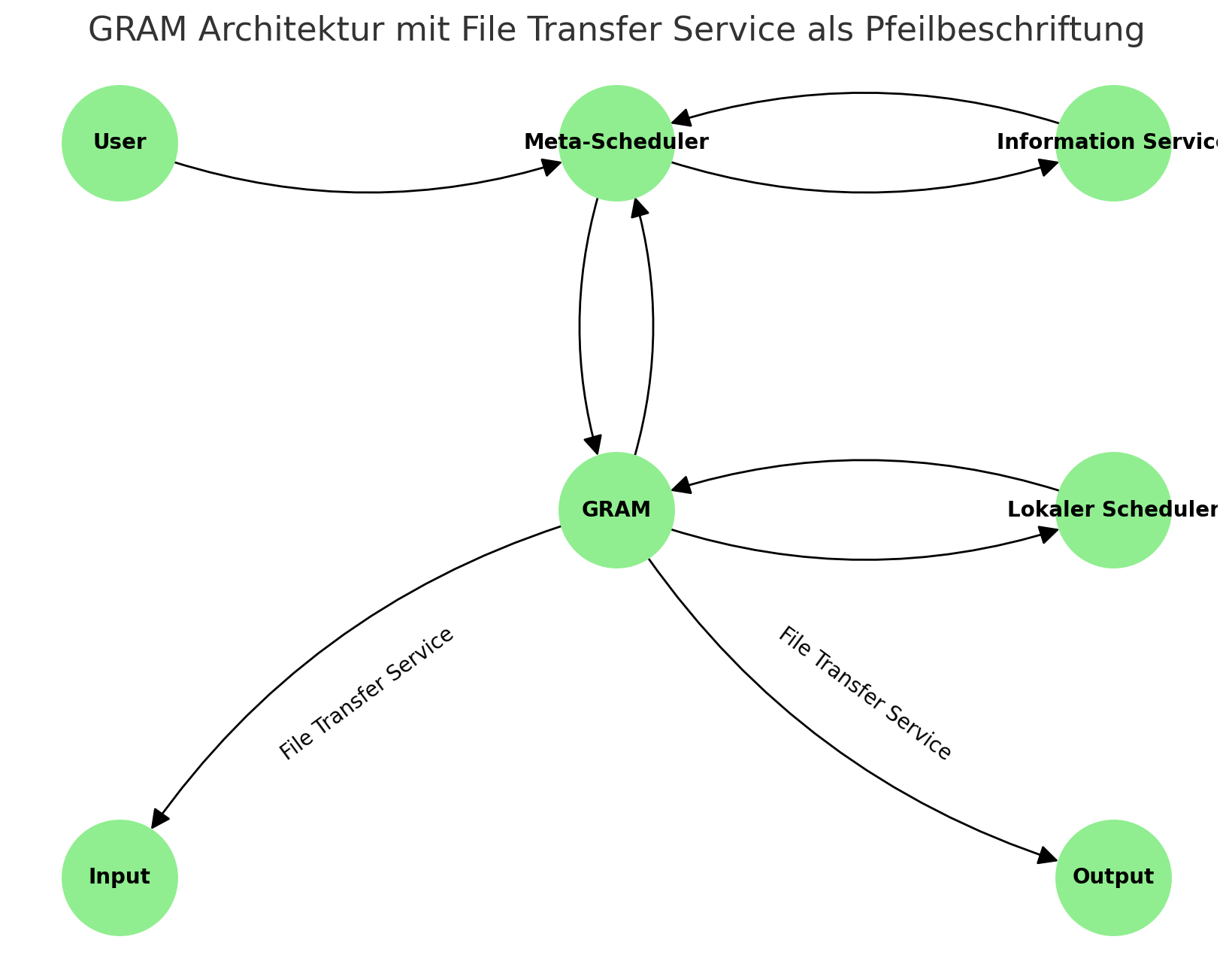
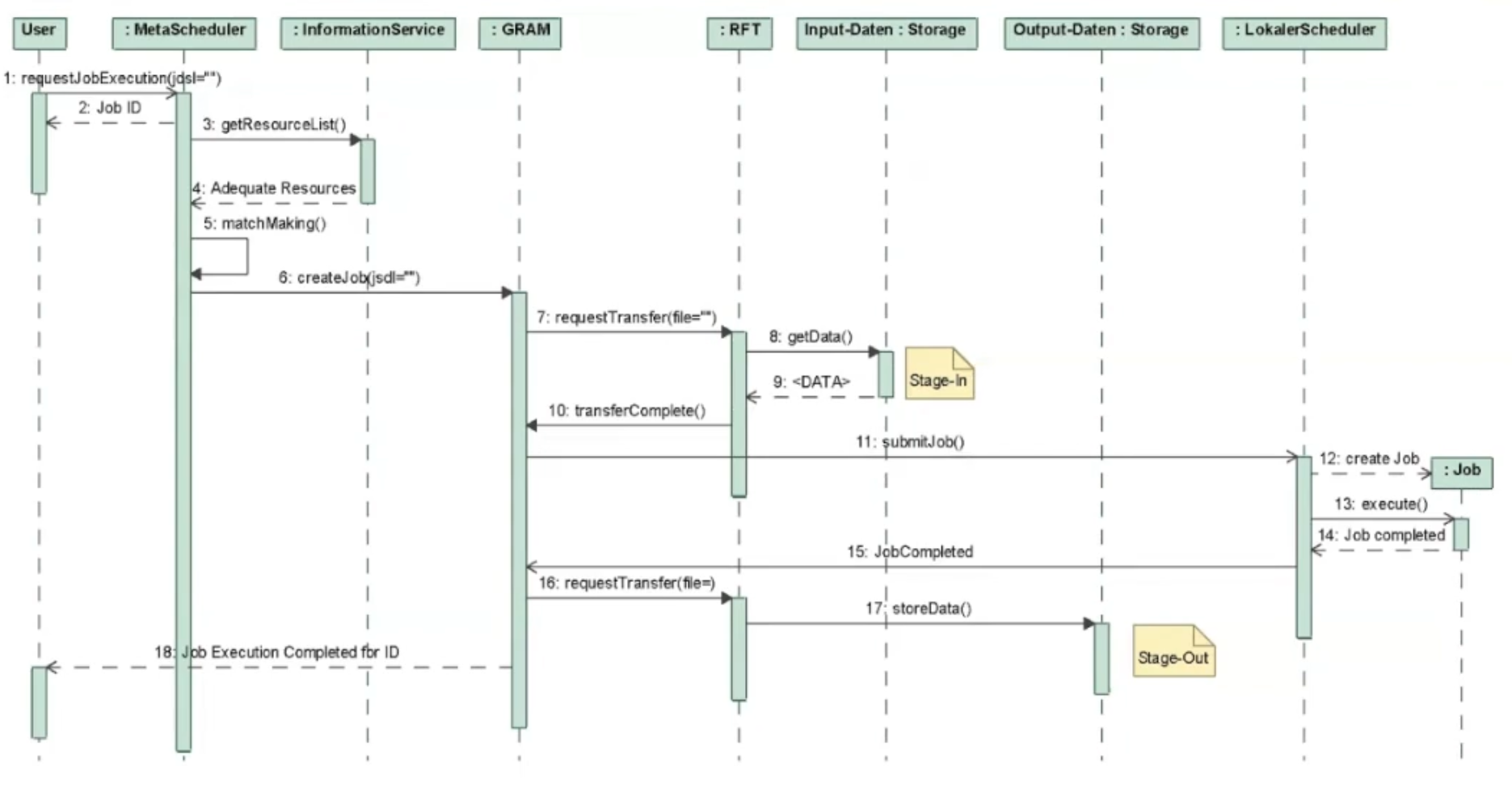
An der Ausführung von Grid-Jobs sind einige Instanzen beteiligt. Geben Sie ein Sequenzdiagramm an, das die Ausführung eines Grid-Jobs beschreibt. Der Einfachheit verzichten Sie auf die Betrachtung von Fehlerfällen. Gehen Sie weiterhin von einem Globus-Umfeld mit einem Metascheduler aus. Berücksichtigen Sie also folgende Objekte:
User
Meta-Scheduler
Information Service
GRAM als Resource Manager
Lokaler Scheduler
Input-Speicher
Output-Speicher
File Transfer Service (zum Beispiel GridFTP)
sequenceDiagram
participant User
participant Server
participant Node
User->>Server: Job submission
Server-->>User: Job ID
Server->>Node: Scheduling
Node-->>Node: Job execution
Node->>Server: Monitoring
Schritt 1 (Meta-Scheduler):
sequenceDiagram
participant U as User
participant MS as Meta-Scheduler
U ->> MS: Job-Anfrage senden
Schritt 2 (information-Service):
sequenceDiagram
participant U as User
participant MS as Meta-Scheduler
participant IS as Information Service
U ->> MS: Job-Anfrage senden
MS->> IS: Welche Ressourcen <br> kommen in Frage?
IS->> MS: Diese Ressourcen <br> kommen in Frage
Schritt 3 (GRAM):
sequenceDiagram
participant U as User
participant MS as Meta-Scheduler
participant IS as Information Service
participant G as GRAM (Resource Manager)
U ->> MS: Job-Anfrage senden
MS->> IS: Welche Ressourcen <br> kommen in Frage?
IS->> MS: Diese Ressourcen <br> kommen in Frage
MS->> G: Dateitransfer &<br> Einreihung in lokalen Scheduler
G->> MS: Dateitransfer
Schritt 3 (Input):
sequenceDiagram
participant U as User
participant MS as Meta-Scheduler
participant IS as Information Service
participant G as GRAM (Resource Manager)
participant I as Input
U ->> MS: Job-Anfrage senden
MS->> IS: Welche Ressourcen <br> kommen in Frage?
IS->> MS: Diese Ressourcen <br> kommen in Frage
MS->> G: Dateitransfer &<br> Einreihung in lokalen Scheduler
G->> MS: Dateitransfer
I->> G: File Transfer von <br> Input Dateien
Schritt 4 (Lokaler Scheduler):
sequenceDiagram
participant U as User
participant MS as Meta-Scheduler
participant IS as Information Service
participant G as GRAM (Resource Manager)
participant I as Input
participant LS as Lokaler Scheduler
U ->> MS: Job-Anfrage senden
MS->> IS: Welche Ressourcen <br> kommen in Frage?
IS->> MS: Diese Ressourcen <br> kommen in Frage
MS->> G: Dateitransfer &<br> Einreihung in lokalen Scheduler
G->> MS: Dateitransfer
I->> G: File Transfer von <br> Input Dateien
G->> LS: Lokale Queue
LS->> G: Returned Queue an GRAM
Schritt 5 (Output):
sequenceDiagram
participant U as User
participant MS as Meta-Scheduler
participant IS as Information Service
participant G as GRAM (Resource Manager)
participant I as Input
participant LS as Lokaler Scheduler
participant O as Output
U ->> MS: Job-Anfrage senden
MS->> IS: Welche Ressourcen <br> kommen in Frage?
IS->> MS: Diese Ressourcen <br> kommen in Frage
MS->> G: Dateitransfer &<br> Einreihung in lokalen Scheduler
G->> MS: Dateitransfer
I->> G: File Transfer von <br> Input Dateien
G->> LS: Lokale Queue
LS->> G: Returned Queue an GRAM
G->> O: Output
Eselsbrücke wie ichs mir mit Storytelling merke (don't judge it works for me :D)
Die Reise eines Grid-Jobs: Ein episches Abenteuer durch das Grid-System
1. Der Beginn der Mission: Ein User und sein Job
Ein User hat eine Mission – einen Grid-Job, der ausgeführt werden soll. Ohne zu zögern, übergibt er ihn dem Meta-Scheduler.
2. Der Meta-Scheduler empfängt den Auftrag
Der Meta-Scheduler nimmt den Job entgegen, mustert ihn und nickt zufrieden: “Ah, ein neuer Job? Hervorragend! Hier ist deine Job-ID, damit du ihn später identifizieren kannst.”
3. Die Suche nach Ressourcen
Doch bevor der Job starten kann, muss der Meta-Scheduler wissen, wo er ausgeführt werden soll. Also wendet er sich an den Information Service: “Welche Ressourcen sind gerade verfügbar?”
Der Information Service wirft einen prüfenden Blick in seine Liste und antwortet prompt: “Hier, diese Ressourcen stehen bereit!“
4. Das große Matchmaking
Der Meta-Scheduler ist zufrieden. Jetzt geht es ans Matchmaking: Er gleicht die Anforderungen des Grid-Jobs mit den verfügbaren Ressourcen ab und erstellt auf dieser Basis die eigentlichen Jobs.
5. Das GRAM kommt ins Spiel
Nun ist es Zeit für den nächsten Schritt. Der Meta-Scheduler reicht die Jobs weiter an das GRAM (Grid Resource Allocation Manager).
Das GRAM nimmt die Jobs entgegen, schaut sich die Aufgaben an und erkennt sofort: “Um diese Jobs auszuführen, brauche ich bestimmte Daten!”
Also beginnt das nächste Abenteuer: Die Datenbeschaffung.
6. Die Beschaffung der Input-Daten
Das GRAM beauftragt das RFT (Reliable File Transfer) mit der Beschaffung der benötigten Daten.
Das RFT geht schnurstracks zum Storage und ruft: “Hey, ich brauche die Input-Daten für einen wichtigen Grid-Job!”
Die Input-Daten sind bereit und antworten: “Hier sind wir! Bereit für den Einsatz!”
Das RFT nimmt die Daten, übergibt sie dem GRAM – und die Reise des Grid-Jobs geht weiter.
7. Die Übergabe an den Local-Scheduler
Nun, da alle notwendigen Daten vorhanden sind, übergibt das GRAM den Grid-Job an den Local-Scheduler.
Dieser nimmt ihn entgegen und ruft entschlossen: “Alles klar, ich erstelle den Job und starte die Berechnung!”
Die Job-Execution beginnt. Es wird gerechnet, verarbeitet, ausgeführt – bis der Job erfolgreich abgeschlossen ist.
8. Das große Finale: Die Ergebnisse
Nachdem die Berechnung abgeschlossen ist, meldet sich der Local-Scheduler beim GRAM: “Mission erfolgreich! Dein Job ist fertig, hier sind die Resultate!”
Doch die Ergebnisse müssen noch sicher gespeichert werden. Also nutzt das GRAM erneut das RFT, um mit den Output-Daten zu kommunizieren. Diese werden schließlich im Stage-Out gesichert.
9. Die große Nachricht an den User
Das GRAM geht zurück zum Meta-Scheduler und sagt: “Job-Execution completed! Deine Job-ID: [ID].”
Der Meta-Scheduler bringt die frohe Botschaft an den User: “Dein Job ist durch! Komm und sieh dir die Ergebnisse an!”
🎯 Mission erfolgreich: Der Grid-Job hat seine Reise durch das System überstanden – von der Anmeldung über die Ressourcenfindung und Datenbeschaffung bis zur finalen Berechnung und Speicherung der Ergebnisse 🚀
Aufgabe 9.2: JSDL und BES
In dieser kleinen Fallstudie werden JSDL und der OGSA Basic Execution Service (BES) in Beziehung gesetzt.
Einführung
JSDL:
JSDL dient – vereinfacht ausgedrückt – der Beschreibung von Anforderungen von Grid-Jobs an Ressourcen. Dazu stellt JSDL ein XML-Vokabular für die Identifizierung von Jobs, deren Ressourcenbedarf und für die Verwaltung benötigter Dateien zur Verfügung (siehe auch hier GFD.56.pdf). Die prinzipielle Vorgehensweise ist in Abbildung 9 dargestellt.
Wichtig ist dabei, dass JSDL nur auf die Beschreibung von Anforderungen zur Job-Submission-Zeit beschränkt ist. JSDL sieht also weder Informationen über Jobs nach deren Submission vor, noch stellt JSDL eine Job Submission-Schnittstelle bereit. Dies ist die Aufgabe des Basic Execution Service (BES).
BES:
Der Basic Execution Service (BES) stellt Web Service-Schnittstellen für das Erzeugen, Überwachen und Kontrollieren von sogenannten Aktivitäten zur Verfügung (siehe GFD.108.pdf). Clients definieren Aktivitäten über die vorher beschriebene JSDL. BES „konsumiert“ also JSDL-Dokumente. BES definiert dafür drei Web Service-Porttypes (siehe Abbildung 10).
Fallschreibung
Sie wollen im Rahmen Ihrer Abschlussarbeit an der LMU Ihr umfangreiches Datenmaterial visualisieren. Sie haben sich entschlossen, dazu die Public Domain Software „gnuplot“ (gnuplot.info) zu verwenden, die Ihnen auf der Basis einer über das Grid gelieferten Input-Datei eine für einen Plotterausdruck vorbereitete Bild-Datei liefert. Sie haben sich außerdem eine Front-End-Applikation geschrieben, die Ihnen Ihre Daten animiert. Das Front-End kennt die URI der Input-Dateien. Diese Daten müssen dem Job ebenso zur Verfügung gestellt werden (stage-in) wie eine gnuplot-Kontrolldatei, die auch eine URI enthalten werden soll. Als Output generiert gnuplot nach (erfolgreichem) Jobende ein png-Bild. Ihr Front-End empfängt diese und versendet Nachrichten auf stderr.
Umsetzung
JSDL:
Das folgende JSDL-Dokument setzt die Fallschreibung um. Sehen Sie sich das Dokument an und beantworten Sie anschließend die Fragen.
5. Wie verändern sich die Input- und Outputdateien über mehrere Job-Ausführungen?
control.txt wird mit overwriteimmer überschrieben. <jsdl:CreationFlag>overwrite</jsdl:CreationFlag>
input.dat wird mit appendan eine eventuell bestehende Datei angehängt (d.h. die Datei kann bei wiederholtem Joblauf wachsen). <jsdl:CreationFlag>append</jsdl:CreationFlag>
output1.png wird ebenfalls mit append geschrieben, so dass auch hier neue Ausgaben an eine bestehende Datei angehängt würden. <jsdl:CreationFlag>append</jsdl:CreationFlag>
Betrachten Sie das vorher angegebene JSDL-Dokument als die Beschreibung einer BES-Aktivität, die vom BES jetzt auf einer entsprechenden Ressource ausgeführt wird (genauer: von einer BES-Implementierung). Dazu unterstützt der BES Factory Porttype die Operation CreateActivity, mit der eine neue Aktivität erzeugt wird. Der Operation wird als Input eine Beschreibung der zu erzeugenden Aktivität gegeben, als Ergebnis wird im Erfolgsfall ein ActivityIdentifier zurückgeliefert.
Mit der folgenden Request Message an eine BES Factory wird eine Aktivität erzeugt. Vervollständigen Sie die Message an der Stelle //X//, so dass der in der vorherigen Aufgabe definierte gnuplot-Job ausgeführt werden kann.
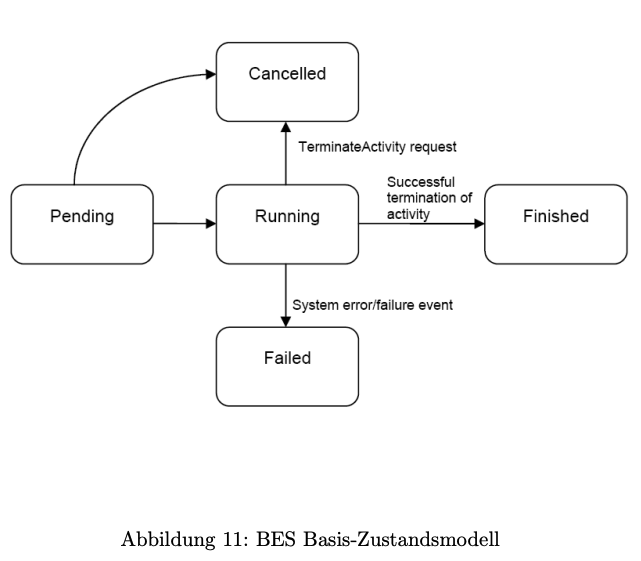
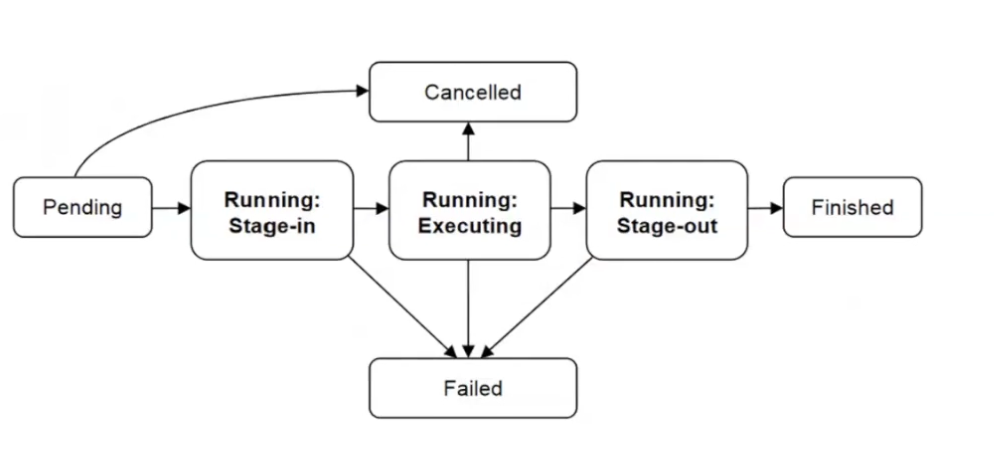
Der Lebenszyklus von BES-Aktivitäten folgt dem in Abbildung 11 dargestellten Basis-Zustandsmodell.
Erweitern Sie dieses Basismodell so, dass das Staging (in und out) von Files berücksichtigt wird.
Eine übliche Erweiterung des BES-Basiszustandsmodells mit Berücksichtigung des File-Stagings besteht darin, für den Eingabe- (Stage-In) und Ausgabe- (Stage-Out) Prozess jeweils eigene Zustände einzuführen. Ein mögliches Diagramm in Mermaid-Syntax könnte beispielsweise so aussehen:
Erläuterung der zusätzlichen Zustände
StagingIn
Dieser Zustand repräsentiert das Einbringen der benötigten Dateien (Input-Files) auf das Zielsystem. Treten Fehler auf, wechselt die Aktivität in den Zustand Failed; wird sie in diesem Zustand abgebrochen, geht sie nach Cancelled.
StagingOut
Dieser Zustand repräsentiert das Herausschreiben der erzeugten Dateien (Output-Files) nach erfolgreichem Durchlauf. Auch hier kann ein Fehler zum Zustand Failed führen, oder ein Abbruch zum Zustand Cancelled.
Übergänge
Von StagingIn nach Running:
Sobald das Einbringen der Input-Dateien erfolgreich abgeschlossen wurde, kann die Aktivität auf der Ressource ausgeführt werden.
Von Running nach StagingOut:
Nach erfolgreichem Abschluss der Berechnung (ohne Abbruch oder Fehler) beginnt das Auslagern der Resultate.
Cancelled und Failed:
Ein TerminateActivity während eines beliebigen aktiven Zustands (StagingIn, Running, StagingOut) führt zum Zustand Cancelled. Tritt ein Fehler auf (z.B. beim Einlesen der Files oder während der Ausführung), so geht die Aktivität in Failed über.
Abschließender Übergang von StagingOut nach Finished:
Ist auch der Stage-Out-Prozess abgeschlossen, wird die Aktivität in den Endzustand Finished überführt.
×
MyUniNotes is a free, non-profit project to make education accessible for everyone.
If it has helped you, consider giving back! Even a small donation makes a difference.
These are my personal notes. While I strive for accuracy, I’m still a student myself. Thanks for being part of this journey!