Computational Intelligence WS24/25
Exercise Sheet 1 — October 31st, 2024
1 Simple Grid Environment
Consider the simple grid world example below, where an agent can move on tiles but is not allowed to stand still, starting from the initial position (S) with the purpose of reaching the goal tile (G). The agent can move between all numbered tiles that are not walls (outside the grid) or blocked (⊗). Execution is stopped on reaching the goal tile.
(i) Task
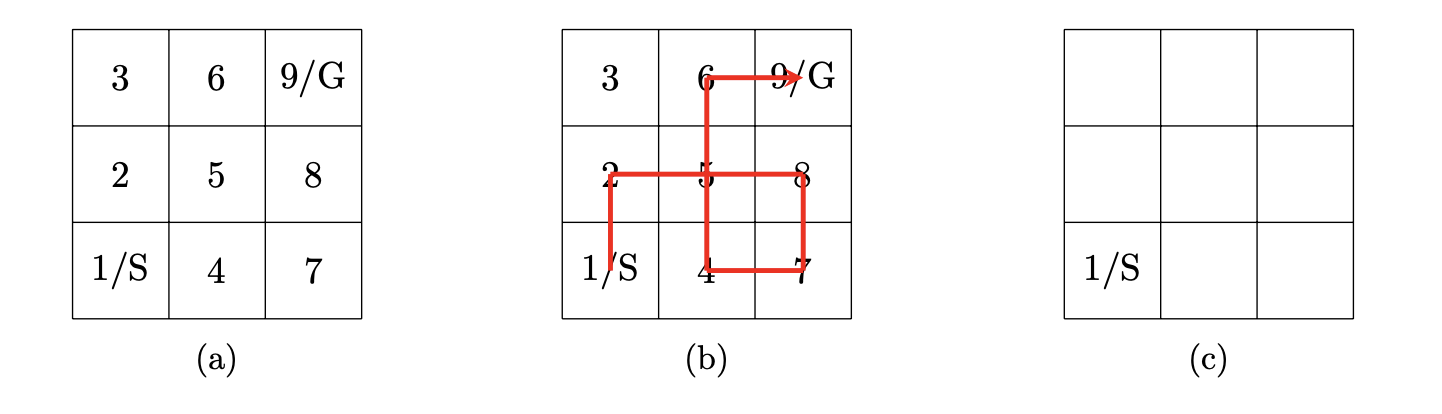
_Consider the small grid-world shown in Example 1a. Define a set of possible observations and a set of possible actions in accordance to the definition given in the lecture. For your definition, what are and ? _
Note: Recall that for any finite set we write for the number of elements in . For infinite sets, we also write .
(ii)
Similarly, for the grid world in Example 1a, define a goal predicate that accepts a policy that (a) finds the way from the start tile (S) to the goal tile (G) in the optimal amount of steps and (b) only steps on tile-numbers which are strictly bigger than any of the tile-numbers visited before. Then provide a solution path, i.e., , for which . Which of the goal classes we have covered in the lecture could fall under?
(iii)
_Now consider the grid world shown in Example 1b. For the given solution trajectory (red line) give and . What is the response from in this case?_
(iv)
Recall that in the lecture we are covering simple (policy) search approaches, one of them being random search (see Algorithm 1 below) with attempts, i.e., . Let us assume that random sampling can only produce policies that always execute valid actions, i.e., never produce sequences of actions that would lead the agent to run into a wall or blocked field. What is the probability of the policy being found by in the grid world Example 1b? Briefly explain your answer.
Algorithm 1 (random search (policy)). Let be a set of actions. Let be a set of observations. Let be a space of goal predicates on policy functions. Let be a goal predicate. We assume that the policy space can be sampled from, i.e., returns a random element from . Random search for samples is given via the function
Hint: You can assume that the probability that a random policy will execute valid action at time step from the set of valid actions at time step is given via .
(v)
Finally, provide a tile-numbering and goal-position in the Template 1c such that is guaranteed to be and explain why. You may set one blocking tile ⊗ (on any tile except the initial position (S)) that cannot be traversed.
2 Squirrel Environment
For scientific purposes, we want to deploy a SquirrelBot, i.e., a small robotic agent that is able to drive across soil and dig for nuts. It can observe its exact location with on a continuous 2D plane representing the accessible soil. In the same plane it can also observe a marked target location that it wants to navigate to. The value of is provided by a MemoryAgent that tries to remember all locations where nuts are buried, but to the SquirrelBot that location (like its own location ) is just part of its observation. The SquirrelBot can execute an action of the form once per time step. The action is resolved by the environment by updating the robot’s own location by and then digging at the new location if . However, all actions that attempt to drive a distance greater than 1 (i.e., ) per time step are completely ignored by the environment.
(i)
Assume that the complete state of the system is given by the position of the SquirrelBot at time step , the position of the marked target location , and a flag marking if the SquirrelBot attempted to dig (after driving) at time step , i.e., the whole system generates a sequence of states for some fixed maximum episode length and . Give a goal predicate so that holds if the agent has at one point in time attempted to dig at a location nearer than 1 to the target location .
Note: The state reflects all information contained in both the agent and the environment, as opposed to the observations which may only contain parts of it. Since there is nothing more we could know about the policy, we can thus also define goal predicates to be evaluated on that system state.
Hint: You can use the function to compute the Euclidean distance between two points in , i.e., .
(ii)
Given a SquirrelBot with the same information , now also give a goal predicate so that holds if the agent has, presumably running out of robot patience, attempted to dig at every second step for exactly 10 steps, coming closer to the goal each time and reaching the goal by digging (within a distance of less than 0.01) on the final, 10th of these steps, thus completing the trajectory.
(iii)
Assume that the whole plane of soil is without obstacles and thus easily navigable for the SquirrelBot. Give a policy that always fulfills the goal predicate eventually regardless of the initial state. Also give ‘s type signature.
Hint: You do not need to construct the fastest such policy.
3 Running Example: Vacuum World
For the various classes of the goal hierarchy it may be intuitively helpful to code the running examples along as we develop them formally.
(i) Implement in Python a simple Vacuum World as we have seen it in the lecture. The implementation should adequately model the concepts of observations and actions, which a policy should be able to exert. A randomly acting policy will suffice initially.
(ii) In the lecture we have discussed the following goal predicate :
should hold iff the agent does not execute the same action for all observations,
or more formally:
In your Python implementation, collect a number of actions and observations for a policy of your choice, then implement and verify the goal predicate .